第一部分 云原生极大的释放了云的红利
云原生的理念经过近10年发展,不断丰富、落地、实践,从早期的概念普及阶段,进入了快速发展期并商业应用阶段。云原生技术以其高效、稳定、兼容性强、快速响应的特点,驱动引领IT企业的业务发展,帮助企业业务快速构建,快速业务拓展。
开源技术主导生态。开源技术也有助于构建高质量的开发人员社区,实现各类人才的协同贡献,加速了技术创新增长。全球云计算厂商都在积极布局云原生开源项目,国内云原生技术领域也涌现出大量的国内公司主导的优质开源项目,如阿里Dubbo、华为ServiceComb贡献给了Apache基金会、容器镜像仓库项目Harbor已经从CNCF(云原生计算基金会)毕业深度应用于企业生产、腾讯TARS贡献给了Linux基金会。
国内云原生热点技术是云原生社区极力追捧者 和 践行者。在近20年IT企业在国内发展,带动存量领域(电商、游戏、门户)、增量领域(社交、金融、支付、各垂直领域)蓬勃发展。 使得国内各企业在硬件利用率、软件分布式能力上,都有所欠缺。 容器技术/云原生技术的中立性、可操作性补齐了短板,获得了头部企业(BAT、TMD)和创新企业(PingCap、SteamNative、支流)的极力投入
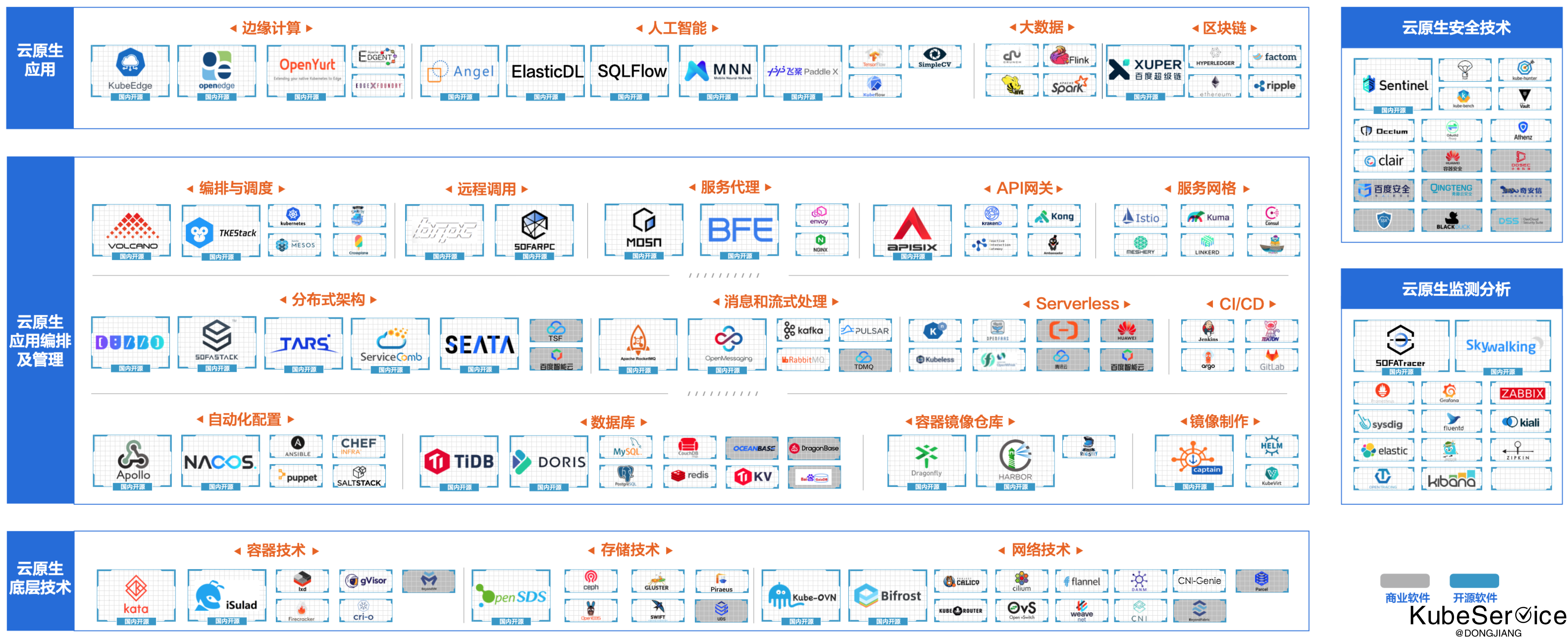
容器技术生态日趋完善,细分项目不断涌现。如上图(图片来自于CNIA官网),相较于早年的技术生态主要集中在容器、微服务、DevOps等技术领域,现如今的技术生态已扩展至底层技术、编排及管理技术、安全技术、智能运维监控技术以及各类场景化应用等众多分支,初步形成了支撑应用云原生化构建的全生命周期技术链。细分领域的技术也趋于多元化发展,国内外出现了很多优秀产品。
第二部分 容器是云原生的基石;容器运行时是容器心脏
总所周知,容器是业务二进制包的标准化封装。而容器运行时(runtime)顾名思义就是要掌控容器运行的整个生命周期。 容器运行时(runtime)将容器解包、分层加载、以标准方式(cgroup+rootfs)申请硬件资源,运行在OS系统上。
业界容器运行时包括:lxc、runc、cri-o、 rkt、cri-containerd、kata-runtime
对于实现运行时的容器工具集合:
runc:Docker EE、Docker CE、pouchlxc:cgrouprkt:rktoci-containerd:containerdkata-runtime:kata container
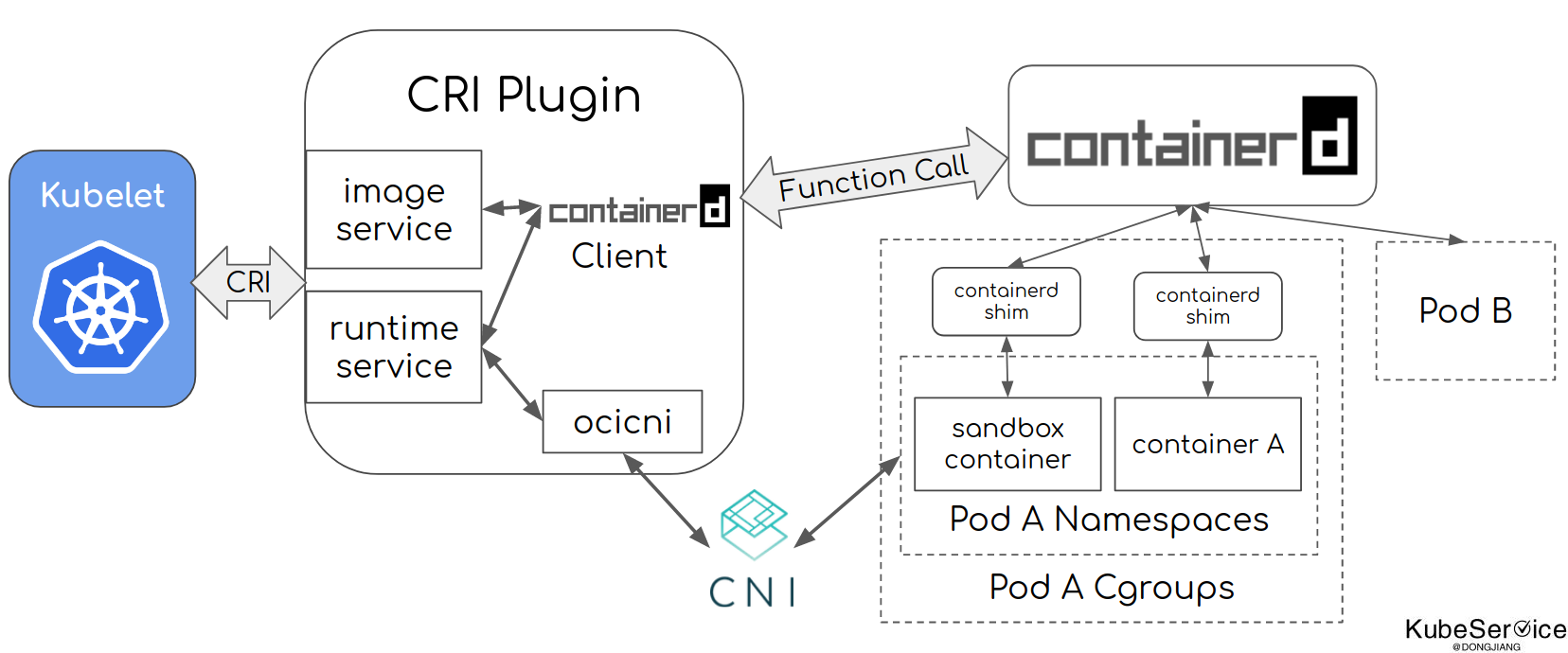
以containerd为例,如图所示(图片来自于containerd官网),核心分2层: image-spec:镜像的生命周期管理;runtime-spec:容器的生命周期管理;
运行时管理步骤:
- kubelet调用CRI插件,通过CRI Runtime Service接口创建pod
- cri通过CNI接口创建和配置pod的network namespace
- cri调用containerd创建sandbox container(pause container )并将容器放入pod的cgroup和namespace中
- kubelet调用CRI插件,通过image service接口拉取镜像,接着通过containerd来拉取镜像
- kubelet调用CRI插件,通过runtime service接口运行拉取下来的镜像服务,最后通过containerd来运行业务容器,并将容器放入pod的cgroup和namespace中。
第三部分 容器镜像存储与容器安全问题爆炸性增长
镜像仓库
容器的核心在于镜像的概念,由于可以将应用打包成镜像,并快速的启动和停止,因此容器成为新的炙手可热的基础设施CAAS,并为敏捷和持续交付包括DevOps提供底层的支持。
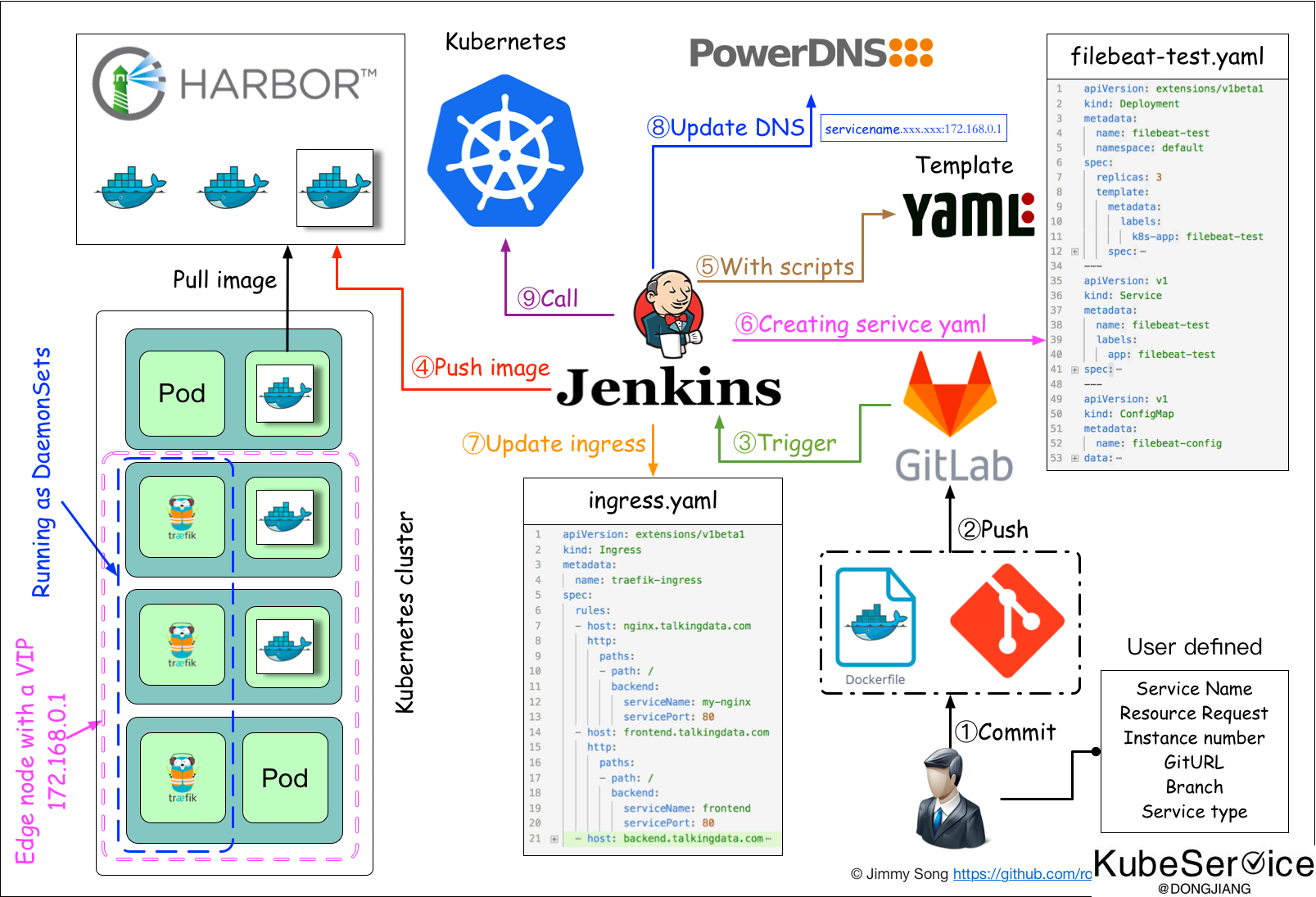
容器镜像仓库就是容器镜像的存储和分发服务。如上图(来自于jimmysong.io网站)
业界开源实现:
- Habor
- Docker Registry
之所以会有这样的服务存在必要性:
提供分层传输机制,优化网络传输Docker镜像是是分层的,而如果每次传输都使用全量文件(所以用FTP的方式并不适合),显然不经济。必须提供识别分层传输的机制,以层的UUID为标识,确定传输的对象。提供WEB界面,优化用户体验只用镜像的名字来进行上传下载显然很不方便,需要有一个用户界面可以支持登陆、搜索功能,包括区分公有、私有镜像。支持水平扩展集群当有用户对镜像的上传下载操作集中在某服务器,需要对相应的访问压力作分解。实现夸区域分发和Node节点提前推送提交将远端镜像推动到目的端,减少数据实时拉取时间、提升容器启动速度;
容器安全
非容器时代下安全防御体系的落地方式主要通过以主机、用户为边界进行安全策略控制和落地。容器技术发展,让Pod(包括os系统image)成指数倍的增长,安全性角度存在更大隐患。 包括:镜像安全、内核安全、容器之间的网络安全、容器Capability限制等等。
容器是基于镜像构建的,如果镜像本身就是一个恶意镜像或是一个存在漏洞的镜像,那么基于它搭建的容器自然就是不安全的了,故镜像安全直接决定了容器安全。通过内部安全镜像仓库(无漏洞的基础镜像),避免了研发人员从互联网拉取带有安全漏洞的镜像到运行环境,从源头消除已知含有漏洞组件的使用,提高了容器安全性。
业界开源实现:
- hadolint
- clair

通用漏洞披露(CVE)数据库获取最新list,和本地镜像各层进行比对,实现漏洞扫描能力
第四部分 Kubernetes编排统一化,编排对象不断扩展延伸
主要介绍K8S,包括简单的历史、K8S各个模块(放一张图),通过介绍主要对象来说明如何抽象、如何解决应用编排的问题
容器编排是自动化容器的部署、管理、扩展和联网的能力。容器编排可以为需要部署和管理成百上千个容器和主机的企业提供便利。包括存储、网络和安全防护等轻松地编排各种服务。容器编排提供了用于大规模管理容器和微服务架构管理工具。容器生命周期的管理有许多容器编排工具可用。
一些常见的方案包括:Kubernetes、Docker Swarm 和 Apache Mesos。
Kubernetes 的目标不仅仅是一个编排系统,而是提供一个规范用以描述集群的架构,定义服务的最终状态,使系统自动地达到和维持该状态。Kubernetes 作为云原生应用的基石,相当于一个云原生操作系统,其重要性不言而喻。
Kubernetes 的诞生
Kubernetes 是 Google 于 2014 年 6 月基于其内部使用的 Borg 系统开源出来的容器编排调度引擎。其实从 2000 年开始,Google 就开始基于容器研发三个容器管理系统,分别是 Borg、Omega 和 Kubernetes。
Google 从 2000 年初就开始使用容器(Linux 容器)系统,Google 开发出来的第一个统一的容器管理系统在内部称之为 “Borg”,用来管理长时间运行的生产服务和批处理服务。由于 Borg 的规模、功能的广泛性和超高的稳定性,一直到现在 Borg 在 Google 内部依然是主要的容器管理系统。
Google 的第二套容器管理系统叫做 Omega,作为 Borg 的延伸,它的出现是出于提升 Borg 生态系统软件工程的愿望。Omega的调度器能够预测资源需求,动态地对在运行中的程序推送配置文件、服务发现、负载均衡、自动扩容、机器生命周期管理、额度管理等能力,这也是后续Kubernetes内置核心调度的能力。
Google 的第三套容器管理系统就是我们所熟知的 Kubernetes,它是针对在 Google 外部的对 Linux 容器感兴趣的开发者以及 Google 在公有云底层商业增长的考虑而研发的。 去掉了 Google 内部绑定的东西后,完全社区化管理的产品。2014 年 Kubernetes 正式开源,2015 年被作为初创项目贡献给了云原生计算基金会(CNCF),从此开启了 Kubernetes 及云原生化的大潮。
容器编排系统的事实标准 Kubernetes

Kubernetes 主要由以下几个核心组件组成:
- etcd 保存了整个集群的状态;
- apiserver 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API 注册和发现等机制;
- controller manager 负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler 负责资源的调度,按照预定的调度策略将 Pod 调度到相应的机器上;
- kubelet 负责维护容器的生命周期,同时也负责 Volume(CSI)和网络(CNI)的管理;
- Container runtime 负责镜像管理以及 Pod 和容器的真正运行(CRI);
- kube-proxy 负责为 Service 提供 cluster 内部的服务发现和负载均衡;
除了核心组件,还有一些推荐的插件,其中有的已经成为 CNCF 中的托管项目:
- CoreDNS 负责为整个集群提供 DNS 服务
- Ingress Controller 为服务提供外网入口
- Dashboard 提供 GUI
- Federation 提供跨可用区的集群
- Cloud Provider API 哪管云端虚拟机的的controller
Kubernetes 是将用户的需求描述(yaml) 通过内部拆解后 维护到Pod的最终状态(status)上,达到用户最终一致效果
第五部分 监控运维智能化、标准化
监控运维领域,在提升可用性、稳定性之外,其重要价值就在于减少重复的人工投入,提升自动化水平,因此企业在评估运维成效的时候,也需要综合考虑监控运维的这一属性为企业带来的时间成本、沟通成本以及效率成本的优化。
运维监控技术主要呈现在logging、metrics 和 tracing可观测性三个维度上。遥测技术(OpenTelemetry)基本定义了一个好的观察系统最后要做到的形态:终态就是实现Metrics、Tracing、Logging的融合,作为CNCF可观察性的终极解决方案。
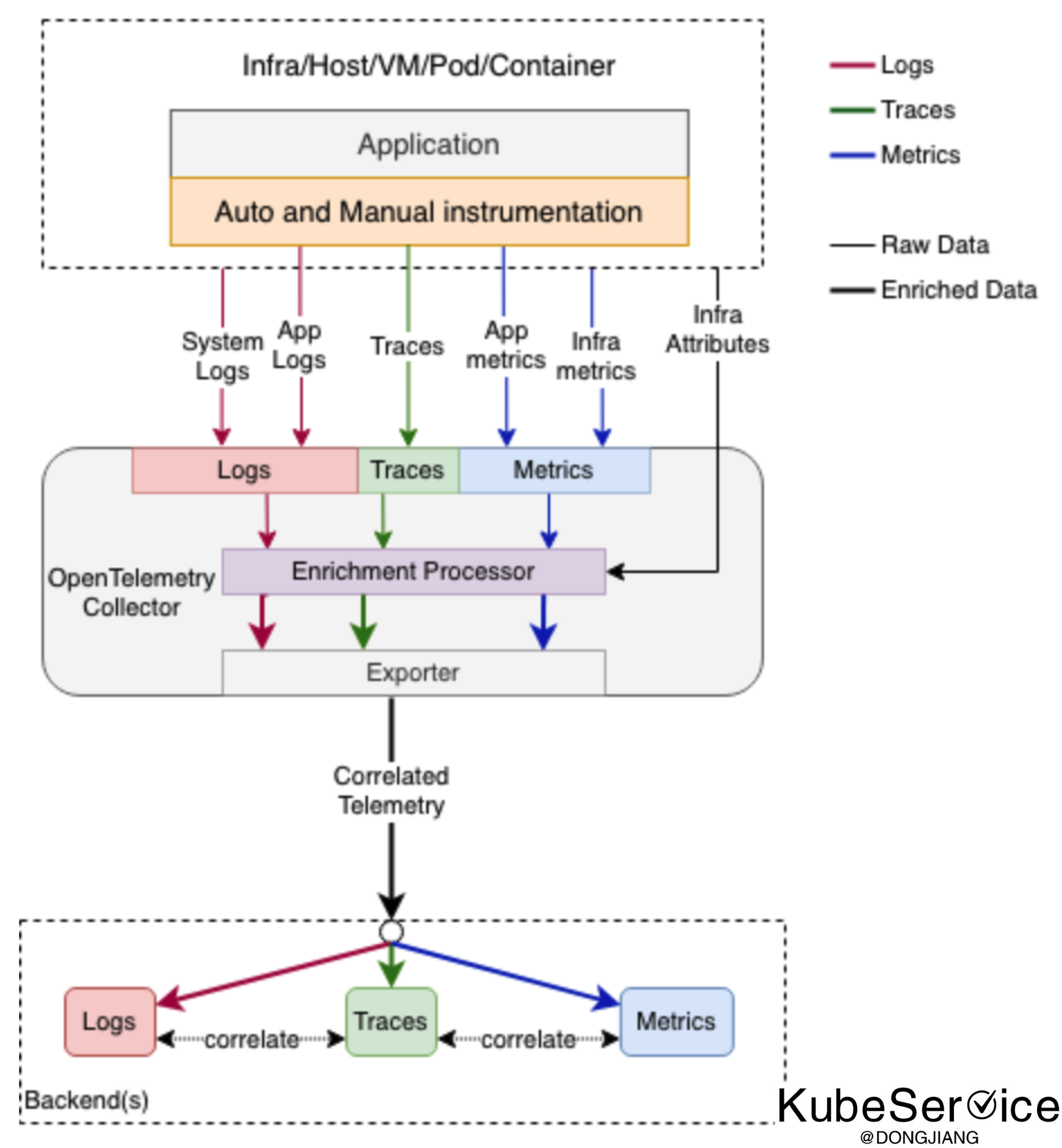
通过统一的数据采集层、数据传输层、最终将数据落地到存储层。支持这个基础设施、网络、主机、虚机、Pod、容器等等不同层面的Metrics、Tracing、Logging三个维度数据,有关联的采集、传输、存储,方便后续关联查询
业界开源实现:
- 标准方面:定义了 OpenTelemetry、 OpenTracing、Openmetrics、Openlogging 接入标准
- 采集层:多语言SDK 和Telemetry Agent
- 传输层:Telemetry Controller
- 存储层:
- Metrics存储: Prometheus、Zabbix、Cat2.0 on M3DB、influxdb、VictoriaMetrics、LinDB、Thanos
- Tracing存储: Jaeger、Tempo、Zipkin、SkyWalking on Cassandra、Influxdb、Elasticsearch
- Logging存储: Loki、Elasticsearch、Druid
- BI展现层: Grafana
优点:可以极大可观察; metircs、logging、Tracing可联动,可聚合分析; 缺点:形态多,选型复杂;企业内烟囱多;
监控运维结合企业产品形态、组织架构、历史能力组合看。国内选型方式,不尽相同
第六部分 服务治理Mesh化,加速传统应用转型
企业的新老应用并存、业务在不同环境、多云部署等是企业应用部署的常态。服务治理旨在利用云的敏捷性,实现新生应用和现有应用的有机协同,构建可平滑演进、快速迭代、功能独立、快速扩张的企业构架。服务治理通过一系列可靠运行的系统保障措施,保证服务高可用,提高资源可视化和免运维能力。
常规的服务治理领域包括:注册发现、配置管理、流量控制、服务降级(熔断限流)、多域切换、备用代理、可观测、灰度发布等。
服务治理实现方式可分为:
- FrameWork类微服务治理
- Mesh化服务网格治理
- 基于FrameWork+Mesh的Stack解决方案
FrameWork类微服务治理
微服务可以解决技术栈异构性的问题。服务微化后没,不在限制实现语言的统一性。国内外微服务框架(如SpringCloud、SpringBoot、Dubbo、Kitx、CloudWego、ServiceComb等),在业务选择接入框架后,可快速获得治理能力。
优点: 承担的业务职责简单服务运行过程是相对透明的,出现问题也能较快发现、定位、回滚
缺点:引入需要业务服务有侵入,需要修改代码或引入框架;
Mesh化服务网格治理
Mesh化服务网格,自立于解决多语言服务治理下工作量double、老旧服务无法更改的服务治理痛点。并进一步完善请求可靠传递轻量级网络代理是服务网格、对应用程序透明的能力
国内外优秀的mesh产品有不少。完成全面(控制面+数据面)产品是istio。以及基于istio控制面实现SofaMesh、Linkerd、Kong Mesh、NGINX Service Mesh等,通过Kubernetes Pod中注入Sidecar方式实现网络劫持和流量代理能力;
优点:
无需修改代码或引入框架,业务无侵入网络流量链路白盒化,可观察性强;
流量控制强
缺点:
必要条件 业务先实现容器化上云(Kubernetes部署)
引入sidecar 代理,增加了环境复杂度
运维人员需要更专业,定位问题、二开等,人员人力需要同步提升
引入sidecar 代理,增加了网络延迟
基于FrameWork+Mesh的Stack解决方案
基于以上两种方案局限性,Stack解决方案提供高性能SDK和无侵入Sidecar两种接入方式统一方式
业界比较有名的是:polarismesh 北极星
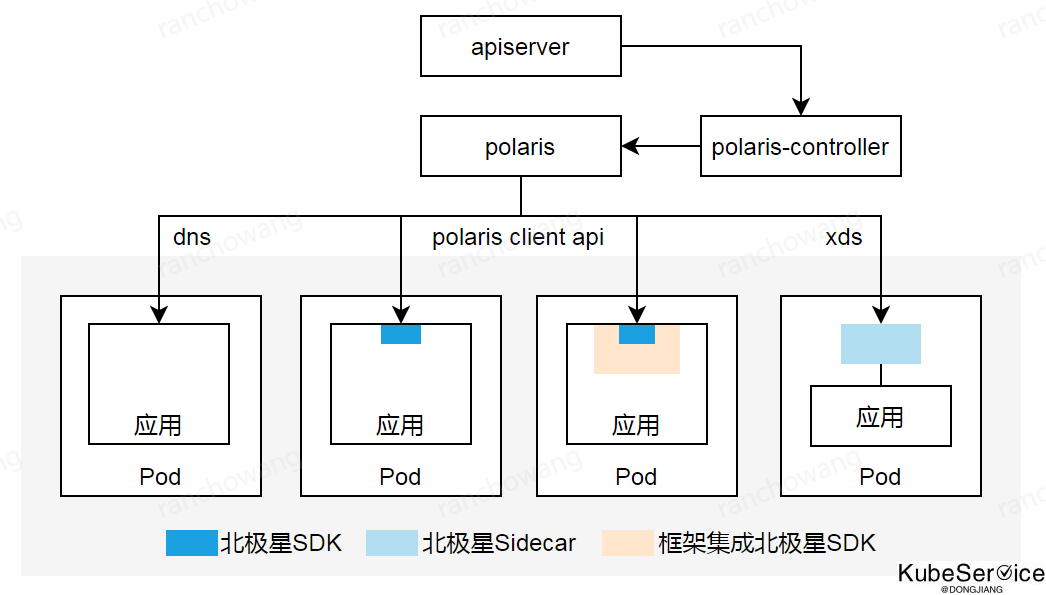
如上图(来自于polarismesh官网),使用统一的mesh控制面,并对了业务服务、微服务、sidecar模式服务统一治理能力
「如果这篇文章对你有用,请随意打赏」
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付
