Kubernetes Node Linux OS 优雅滚动替换方案
Kubernetes集群上,更换 node os操作系统,无疑是开着飞机换引擎 保证业务平稳过度的前提下,Linux OS操作系统如何优雅更换?
举个例子:目前有一套Kubernetes集群,500台Node、20000个Pod、5000个Service. 包括:jobs、stateful pod、stateless pod、daemonset、configmap\secrets
大体可以执行的大步调, 大体有以下两种:
-
集群node按
步进替换更新 :集群中先将 N台 node标记不可调度; 将其已有的pod 驱逐到其它节点; 下线重新装系统, 重新纳管node节点将该 node 标记不可调度,并将其已有的 pod 驱逐到其它节点,这样下线node,重新安装机器 OS 系统:
$ kubectl cordon <node-name>
$ kubectl drain <node-name>
$ reset linux os //安装新系统
$ systemctl start kubelet // 重新纳管node节点
-
服务
集群迁移:准备现有集群 1/10 机器; 安装新Kubernetes + Node Linux OS系统; 将服务部署到新集群;旧集群驱逐pod、 下线node、重新安装新系统、纳管node到新系统;a.准备新集群部署新服务:
IP网段划分、新旧K8S集群统一Subnet、部署基础监控、告警、调用链路、pod<->pod互通等b.将服务部署到新集群: 租户
namespace、serviceaccout、rabc等,新旧K8S集群同步; 选择租户服务迁移新集群(新服务 + 数据迁移)c.新服务流量迁移: SLB切流到新服务
d.旧K8s集群,node驱逐、下线、重新安装新系统、纳管node到新K8s
e.重复 b-d 操作
更多细节准备
方案一:集群node按步进替换更新
对节点进行维护或进行版本升级等操作,操作之前需要对节点执行驱逐 (kubectl drain),驱逐时会将节点上的 Pod 进行删除,以便它们漂移到其它节点上,当驱逐完毕之后,节点上的 Pod 都漂移到其它节点了,这时我们就可以放心的对节点进行操作了。
驱逐存在的问题
有一个问题就是,驱逐节点是一种有损操作,驱逐的原理:
- 封锁节点 (设为不可调度,避免新的 Pod 调度上来)。
- 将该节点上的 Pod 删除。
- ReplicaSet 控制器检测到 Pod 减少,会重新创建一个 Pod,调度到新的节点上。
这个过程是先删除,再创建,并非是滚动更新,因此更新过程中,如果一个服务的所有副本都在被驱逐的节点上,则可能导致该服务不可用。
我们再来下什么情况下驱逐会导致服务不可用:
- 服务存在单点故障,所有副本都在同一个节点,驱逐该节点时,就可能造成服务不可用。
- 服务没有单点故障,但刚好这个服务涉及的 Pod 全部都部署在这一批被驱逐的节点上,所以这个服务的所有 Pod 同时被删,也会造成服务不可用。
- 服务没有单点故障,也没有全部部署到这一批被驱逐的节点上,但驱逐时造成这个服务的一部分 Pod 被删,短时间内服务的处理能力下降导致服务过载,部分请求无法处理,也就降低了服务可用性。
方案重点准备点
针对第一点,我们可以使用前面讲的 Kubernetes Pod 打散几种处理方法 避免单点故障。
针对第二和第三点,我们可以通过配置 PDB (PodDisruptionBudget) 来避免所有副本同时被删除,驱逐时 K8S 会 “观察” nginx 的当前可用与期望的副本数,根据定义的 PDB 来控制 Pod 删除速率,达到阀值时会等待 Pod 在其它节点上启动并就绪后再继续删除,以避免同时删除太多的 Pod 导致服务不可用或可用性降低,下面给出两个示例。
示例一:保证驱逐时 nginx 至少有 90% 的副本可用:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
minAvailable: 90%
selector:
matchLabels:
app: nginx
示例二: 保证驱逐时 zookeeper(可能存在脑裂问题)最多有一个副本不可用,相当于逐个删除并等待在其它节点完成重建:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: zk-pdb
spec:
maxUnavailable: 1
selector:
matchLabels:
app: zookeeper
方案适用范畴
适用于:无状态服务、Job类服务偏多,不需要数据迁移(无LocalPV)的业务集群;
方案二:服务集群迁移
对于重度依赖宿主机、本地卷等高并发K8s集群,对于启停Pod、Pod漂移会产生业务敏感的。集群迁移更加合适。 保证这类pod只会漂移一次
服务集群迁移 方案, 可确保业务迁移过程中,各个Pod只会漂移一次
而 集群node按步进替换更新 方案, 业务Pod驱逐会很频繁
方案重点准备点
-
新集群部署新服务:
IP网段划分、新旧K8S集群统一Subnet、部署基础监控、告警、调用链路、pod<->pod互通等, 都是为了保证 新旧集群Pod之间网络可互通 防止业务pod直接有相互调用
防止业务pod直接有相互调用 -
将服务部署到新集群: 租户
namespace、serviceaccout、rabc等,新旧K8S集群同步; 选择租户服务迁移新集群(新服务 + 数据迁移)通过
ResourceDistribution跨命名空间,跨集群下的命名空间数据同步 或者 通过kubectl get all -n xxx -o yaml
示例一:获得kube-system一致性问题
$ kubectl get all -n kube-system -o yaml
apiVersion: v1
items:
- apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2022-05-04T11:39:08Z"
generateName: coredns-78fcd69978-
labels:
k8s-app: kube-dns
pod-template-hash: 78fcd69978
name: coredns-78fcd69978-7zqmd
namespace: kube-system
ownerReferences:
- apiVersion: apps/v1
...
- apiVersion: v1
data:
Corefile: |
cluster.local:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
...
数据迁移是难点。 如果可以做到双写,可以先将从节点先迁移,主从切换,再迁移目前的从节点
- 新服务流量迁移: SLB切流到新服务
通过外部slb,将业务流量迁移到新集群service上来
- 旧K8s集群,node下线、重新安装新系统、纳管node到新K8s
重复方案一处理
方案适用范畴
重度依赖宿主机、本地卷等高并发K8s集群,对于启停Pod、Pod漂移会产生业务敏感的。
TODO: Future
未来:业务可以做到多集群混合部署、流量混合调度、K8s平台可以做到控制面做到集群联邦调, 非常方便利于业务扩展,底层Node、K8s版本更换等
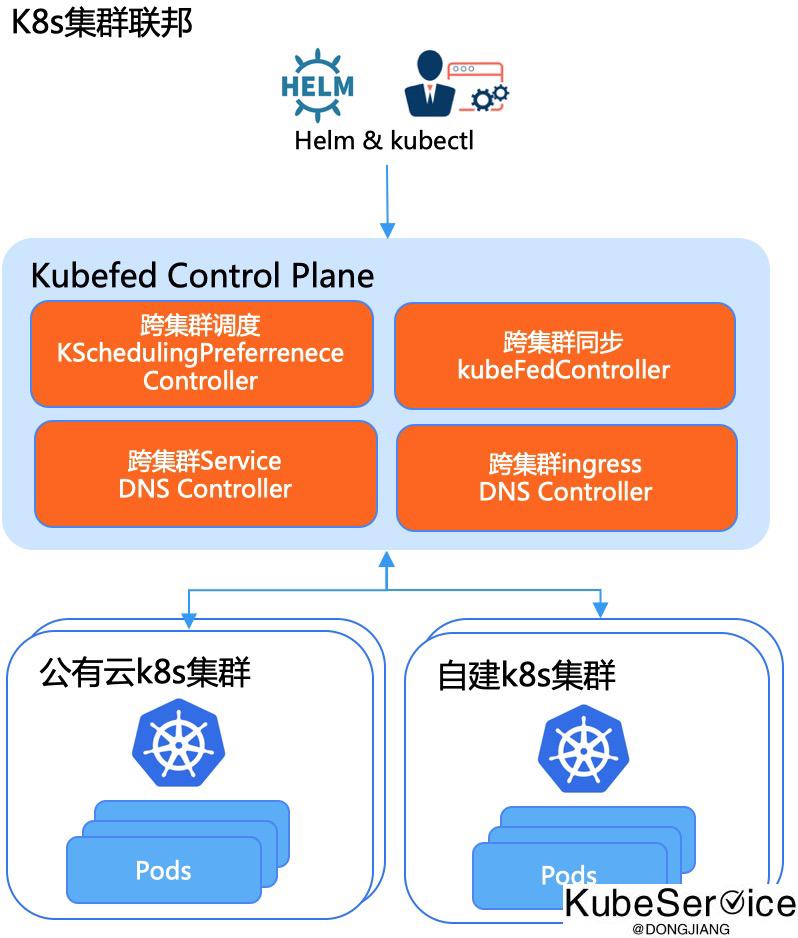
两种方案对比
| 能力点 | 集群node按步进替换更新 |
服务集群迁移 |
|---|---|---|
| 迁移步骤 | 优 | 中 |
| 变更时常 | 中 | 长 |
| 业务稳定性 | 中 | 高 |
| 业务中断 | 低 | 中 |
总结:对于业务无状态 集群,使用方案一,加大每次step步进快速完成; 对于业务高稳定性、本地数据卷, 使用方案二 做好数据迁移步骤(每一类服务都不一样)
Tips: OpenEuler 适配 Kubernetes 问题
-
- OpenEuler 补丁安装,yum源、ntp源配置完成
-
- cni 目录需要 软链 or
--root-path单独设置下 (无/opt/cni/bin目录,只是有/usr/libexec/cni/目录)
- cni 目录需要 软链 or
-
- 如果CRI使用docker,需要使用 docker oe版本(OpenEuler OS 二开适配过的版本)
-
- Node机器上,kubelet和docker 的
cgroup driver必须使用cgroupfs。 设置方式:KUBELET_KUBEADM_ARGS=”–cgroup-driver=cgroupfs"
- Node机器上,kubelet和docker 的
「如果这篇文章对你有用,请随意打赏」
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付
