基于旁路的Prometheus监控体系构建
基于 kubernetes 集群之外的 OPSCenter 建设.
在此先提两个经常被问到问题:
Kubenetes中已有很晚上的监控体系(cAdvisor、metrics-server、kube-state-metrics,kube-prometheus-stack)等,不同层面实现, 是否还有必要构建独立旁路OPScenter呢?- 构建
旁路OPSCenter可以解决什么问题? 是至上而下的任务, 还是至下而上的产品?
先回答第一个:
a. 虽然kubernetes生态中,有不少优秀的监控组件和方案,但这些组件(除了类agent外), 基本上都是解决本Kubenetes内各类资源的问题。 不能解决一个产品多区域、多个Kubenetes、即有传统应用和容器应用等,聚合采集监控报警。 跳出容器以为,可独立收集、存储、聚合计算、监控报警 和 预测
b. 旁路OPScenter 并不是完全独立,是在使用kubenetes内置采集基础上,将采集数据吐出集群自外, 对实现对不同集群的同比、环比、方差对比,并可实现长久保存
c. 旁路OPScenter不暂用业务kubenetes集群的资源,可极大保证业务资源部署和调度
d.中心化OPSCenter 可以将数据准备、标准落地,无论是 领导视图驾驶舱 和 员工工作图表 ,对数据口径一致、数据聚合可视化呈现一致;
对于第二个问题,先看完以下核心设计后,再解答!
监控体系设置
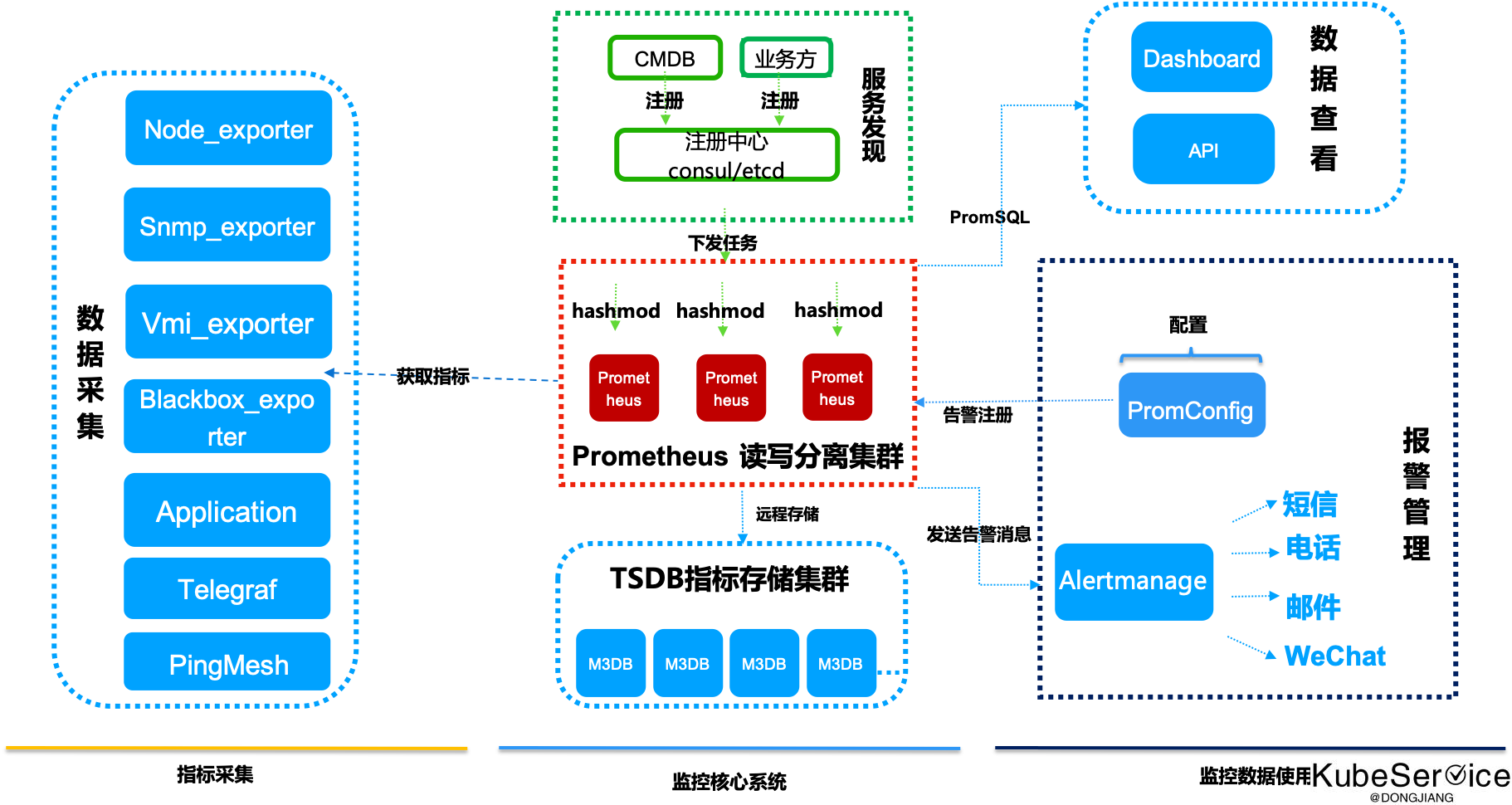
监控体系设计核心都是3大块:
数据采集
数据存储
数据呈现与数据使用
1.监控在于 数据采集维度 多样性
通过不同的采集器(xxx_exporter) 进行不同维度的数据采集
a. Node exporter: 采集基于Linux主机相关信息数据,包括:cpu、load、filesystem、meminfo、network、disk等基础监控指标
b. Snmp exporter: 采集网络设备的信息数据,包括:路由器、交换机、AP、网络打印机等设备的信息采集
c. Vmi exporter: 采集Window设备数据,包括:window server 和 员工window笔记本
d. blackbox exporter: 采集网络互通性数据,包括: dns、ssh、tcp、udp、icmp、http 和 smtp/pop 等互通性数据
f. 应用自定义暴露的metrics采集
g. Telegraf: 采集中间件只定义数据格式和结构
h. pingmesh: 采集overlay网络互通性验证
2.通过注册中心协调管理采集target任务
Prometheus是基于Pull模式的监控系统,显然无法继续使用的static_configs的方式静态的定义监控目标。而对于Prometheus而言其解决方案就是引入一个中间的代理人(服务注册中心),这个代理人掌握着当前所有监控目标的访问信息,Prometheus只需要向这个代理人询问有哪些监控目标即可, 这种模式被称为服务发现。
prometheus可根据不同的服务发现机制实现监控的任务的发现和采集。
可以基于注册中心、本地文件file、Kubernetes apiserver、http接口、DNS等等很多种形式进行发现.
3.多个 Prometheus hashmod 平分监控任务
在中心测OPSCenter中会监控上万套集群、十万Node、百万Pod时,采集任务不能在一天机器上完成,如何将任务平均分配到不同机器上执行,需要将百万级任务进行水平分片(Horizontal Sharding), 即: 有多个分片的 Prometheis,每个分片收集目标的一个子集并将它们聚合到分片中
global:
external_labels:
shard: 1 # 这是第二个分片。这可以防止分片之间的冲突。
scrape_configs:
- job_name: some_job
# 在这里添加常用的服务发现,例如 static_configs
relabel_configs:
- source_labels: [__address__]
模数: 4 # 4 shards
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$ # 这是第二个分
片动作:保持
4.Prometheus server进行读写分离
将整个Prometheus server 分离出3个组:
一个用于
数据收集- 写集群.
一个用于
Grafana/Dashboard图表呈现- 读集群
另一个用于
报警计算、/同比环比差分计算- 计算读集群
写集群:请求QPS比较固定,和采集的target数量成正比
读集群:和dashboard开启的业务会话数和接口请求时需window窗口大小有关
计算读集群:与alertmanager定制的报警有关
5.TSDB进行落盘存储
HA + 远程存储:除了基础的多副本 Prometheus,还通过 Remote write 写入到远程存储,解决存储持久化问题
# Remote write configuration (TSDB).
remote_write:
- url: "http://127.0.0.0.1:3242/api/prom_write"
# Configures the queue used to write to remote storage.
queue_config:
# Number of samples to buffer per shard before we start dropping them.
capacity: 1000000
# Maximum number of shards, i.e. amount of concurrency.
max_shards: 8
# Maximum number of samples per send.
max_samples_per_send: 5000
remoteRead:
- url: "http://127.0.0.0.1:3242/api/prom_read"
readRecent: true
6.监控和报警统一和分离
监控,广义是指 运维监控大体系. 狭义:在监控体系中的 dashboard
报警,是指最新的一个点数据,是否不符合条件,而进行聚合通知(短信、邮件、微信、钉钉、电话语音)等
「如果这篇文章对你有用,请随意打赏」
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付
