基于blackbox构建的Pingmesh体系
背景
数据中心自身是极为复杂的,其中网络涉及到的设备很多就显得更为复杂,一个大型数据中心都有成百上千的节点、网卡、交换机、路由器以及无数的网线、光纤。在这些硬件设备基础上构建了很多软件,比如搜索引擎、分布式文件系统、分布式存储等等。在这些系统运行过程中,面临一些问题:如何判断一个故障是网络故障?如何定义和追踪网络的 SLA?出了故障如何去排查?
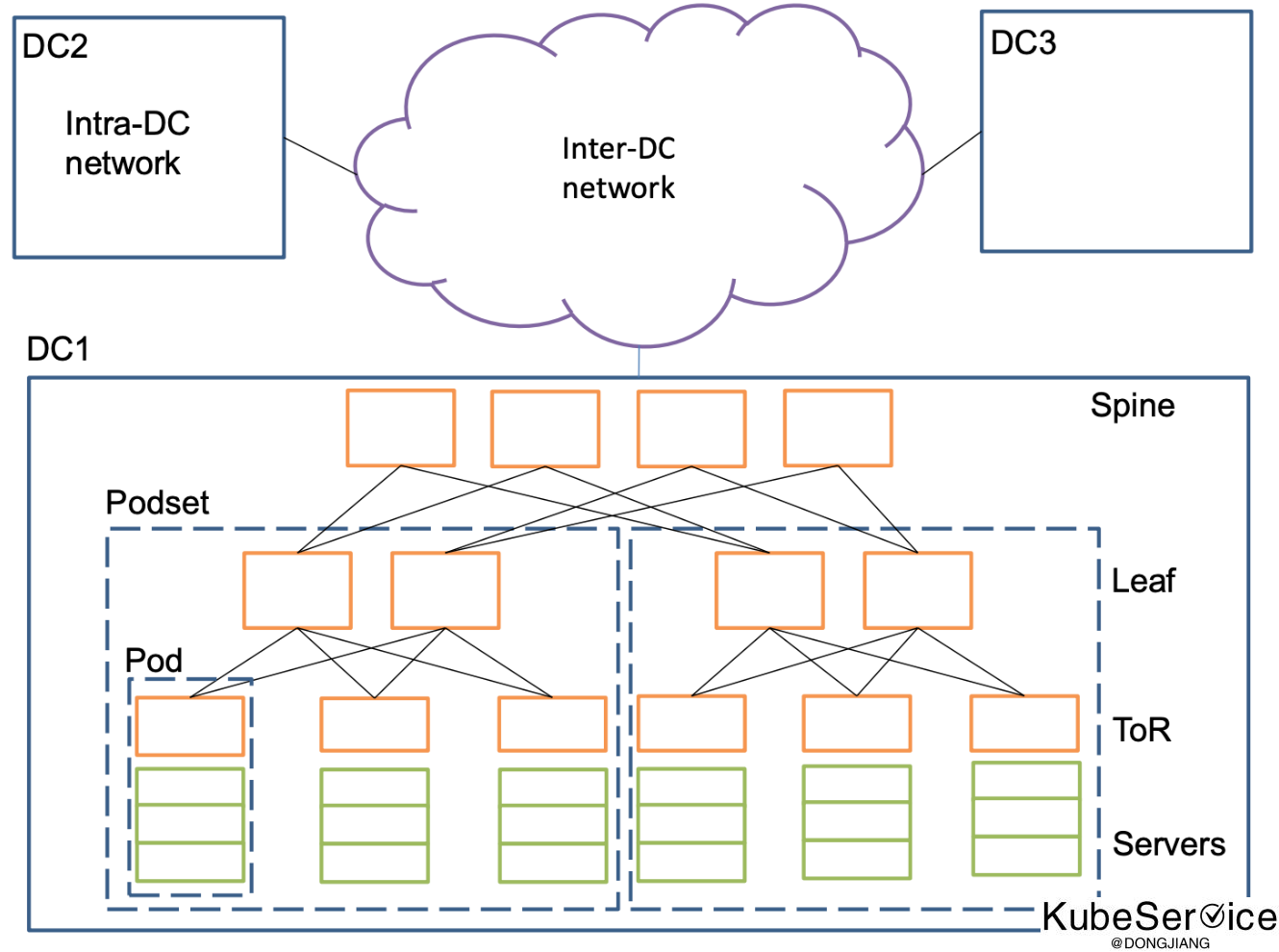
网络性能数据监控 就比较困难实现。 如果单纯直接使用 ping 命令收集结果,每台服务器去 ping 剩下 (N-1) 台,也就是 N^2 的复杂度,稳定性和性能都存在一些问题。
举个例子:
如果IDC中有10000台服务器,ping的任务就有,10000*9999 任务, 如果一台机器有多IP请求,结果再翻倍。
对于数据存储也是一个问题,如果是每30s进行一次ping, 一次ping 需要 payload大小是64bytes
数据存储量: 10000*9999*2*64*24*3600/30 = 3.6860314e+13 bytes = 33.52TB
是否只记录fail和timeout的记录,可以节约99.99%的存储空间
业界实现
本体系是基于微软Pingmesh论文一种增强实现.
原微软Pingmesh论文地址: 《Pingmesh: A Large-Scale System for Data Center Network Latency Measurement and Analysis》
对于微软Pingmesh是网络监控中一个很好突破。(具体可认真读原文)
但是在实际使用中也有不少局限性:
-
agent数据流: 对于
Agent每次ping完都是记录到log中,再通过基础设施进行log数据收集,使用日志分析系统加大了系统复杂性。 -
Ping 模式支持: 只能支持
UDP模式, 对于DNS tcp、ICMP ping等支持比较缺少。 -
Ping维度:只能支持
IPv4ping。 但很多场景需要支持 是否公网互联互通等domain/dnsping -
不支持手动实时尝试ping: 可基于
balckbox-exporter网络探测实现 -
不支持ipv6
Pingmesh升级后的架构
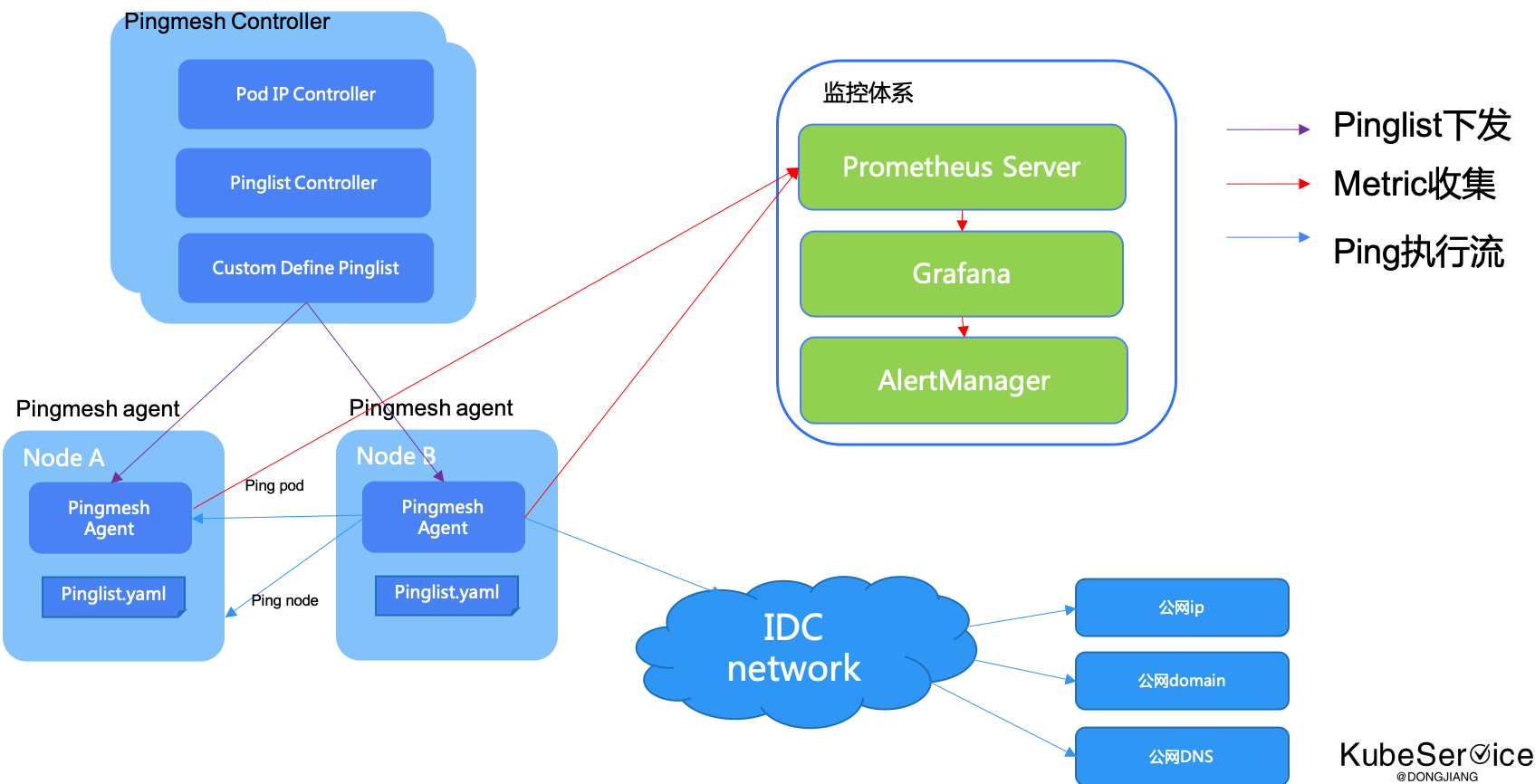
Controller
Controller 主要负责生成 pinglist.yaml 文件。 pinglist 的生成来源有3个方向:
通过
IP Controller自动获取到整个集群的podIP 和 nodeIp list
通过
Pinglist Controller活动Agent Setting配置
通过
Custom Define Pinglist在pinglist.yaml文件中补充 外部地址。 支持dns地址、外部http地址、domain地址、ntp地址、Kubenetes apiserver地址等等
Controller 在生成 pinglist 文件后,通过 HTTP/HTTPS 提供出去,Agent 会定期获取 pinglist 来更新 agent 自己的配置,也就是我们说的拉模式。Controller 需要保证高可用,因此需要在 Service 后面配置多个实例,每个实例的算法一致,pinglist 文件内容也一致,保证可用性
Agent
每个 ping 动作都开启一个新的连接,为了减少 Pingmesh 造成的 TCP 并发. 两个server ping 的周期最小是 10s,Packet 大小最大 64kb。
setting:
# the maximum amount of concurrent to ping, uint
concurrent_limit: 20
# interval to exec ping in seconds, float
interval: 60.0
# The maximum delay time to ping in milliseconds, float
delay: 200
# ping timeout in seconds, float
timeout: 2.0
# send ip addr
source_ip_addr: 0.0.0.0
# send ip protocal
ip_protocol: ip6
mesh:
add-ping-public:
name: ping-public-demo
type: OtherIP
ips :
- 127.0.0.1
- 8.8.8.8
- www.baidu.com
- kubernetes.default.svc.cluster.local
并且做了过载保护
- 如果
pinglist中 数据很多, 在一个周期(比如10s)处理不完, 会保证本次处理完成后,在执行下一次, 优先一个轮回完成 - 配置可以设置
agent并发线程数,确保pingmesh agent对整个集群影响小于千分之一 - metrics中是通过
Promethrus Gauge, 在每个周期中单独计算
# HELP pingmesh_fail ping fail
# TYPE pingmesh_fail gauge
pingmesh_fail{target="8.8.8.8",tor="ping-public-demo"} 1
# HELP pingmesh_duration_milliseconds duration of ping rtt
# TYPE pingmesh_duration_milliseconds gauge
pingmesh_duration_milliseconds{target="docker.io",tor="ping-public-demo"} 245
- 为了确保 ping的请求在一个
时间窗口interval中平均发出, 对请求job 做了内存态计算,在并发协程上做了ratelimit
网络状况设计
通过pinglist.yaml设置中的interval时间窗口:
- 请求超过了
timeout时间, 将请求标记为ping_fail - 请求超过了
delay但没有超过timeout时间, 将请求标记为ping_duration_milliseconds - 请求没有超过
delay,在metrics接口中不记录
与promtheus集成
将以下文本添加到promtheus.yaml的scrape_configs部分, pingmeship为server的ip
scrape_configs:
- job_name: net_monitor
honor_labels: true
honor_timestamps: true
scrape_interval: 60s
scrape_timeout: 5s
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- $pingmeship:9115
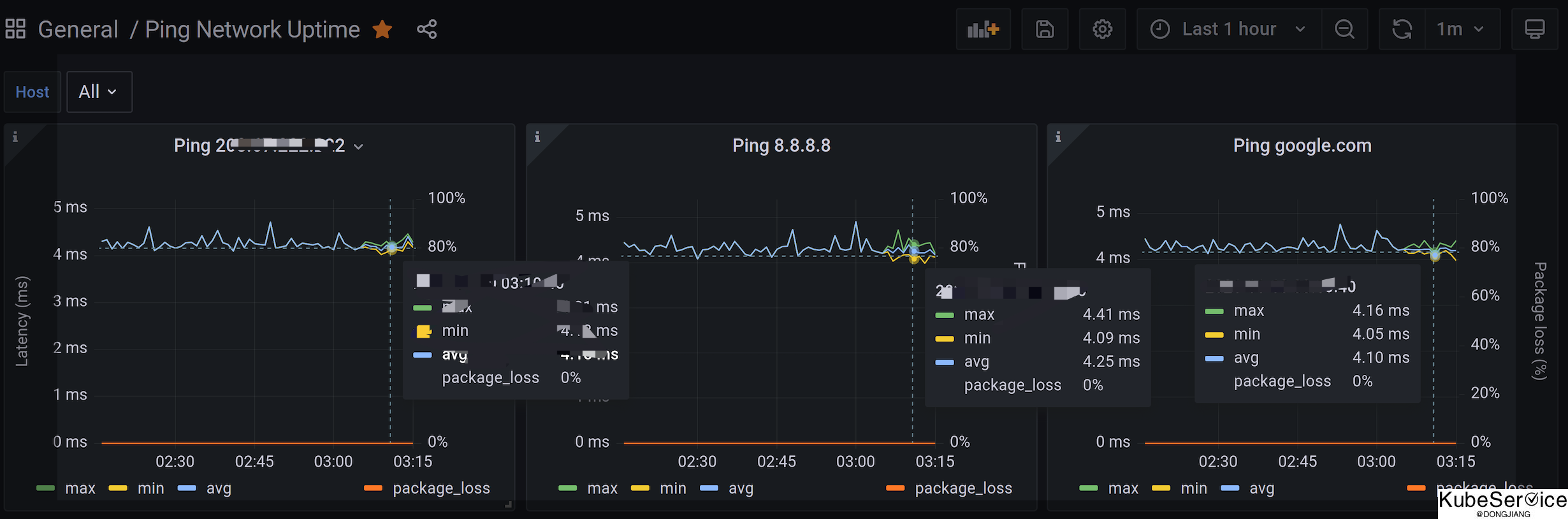
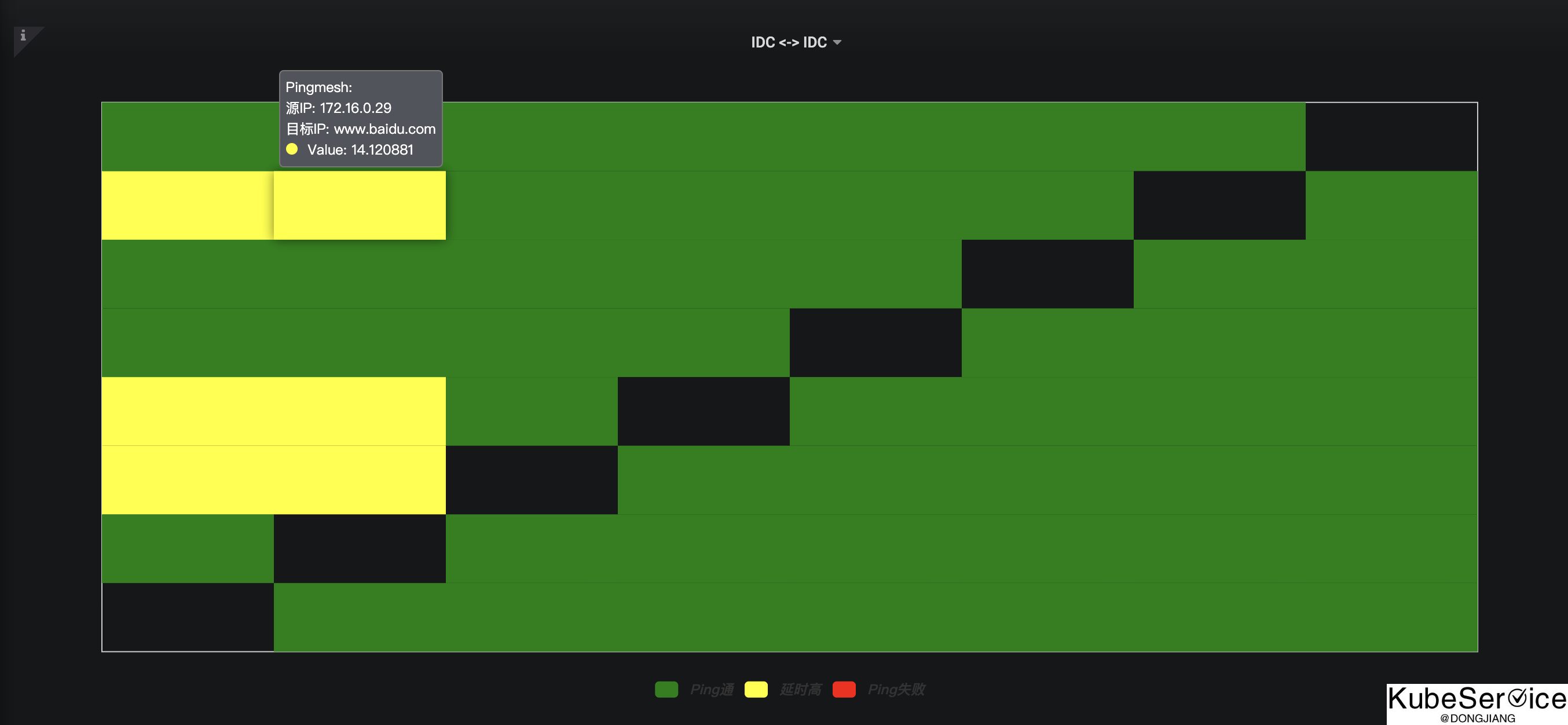
与监控grafana结合
「如果这篇文章对你有用,请随意打赏」
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付
