技术方案之 基于节点真实负载情况调度:crane-scheduler-plus
crane-scheduler 解决了Kubernetes仅仅基于资源的 resource request 进行调度,然而 Pod 的真实资源使用率 real-used,往往与其所申请资源的 request/limit 差异很大,这直接导致了集群负载不均, 跟严重者会导致节点Pod被驱逐
通常遇到的现象:
-
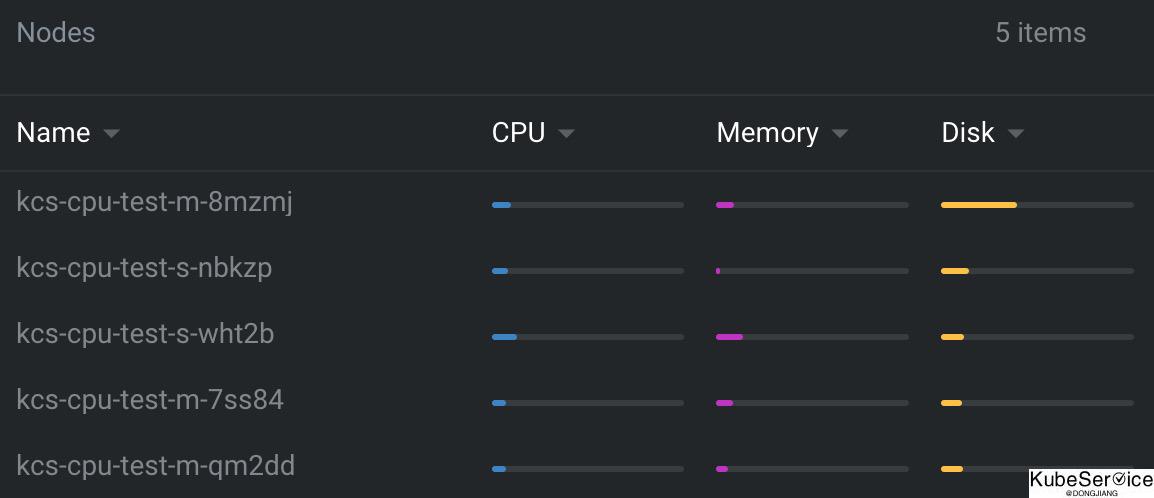
1.集群中的部分节点,资源的真实使用率远低于 resource request,却没有被调度更多的 Pod,这造成了比较大的资源浪费;
-
2.而集群中的另外一些节点,其资源的真实使用率事实上已经过载,却无法为调度器所感知到,这极大可能影响到业务的稳定性;
与上云的最初目的相悖,为业务投入了足够的资源,却没有达到理想的效果。
1. 原生crane-scheduler
Crane-scheduler 基于集群的真实负载数据构造了一个简单却有效的模型,作用于调度过程中的 Filter 与 Score 阶段,并提供了一种灵活的调度策略配置方式,从而有效缓解了 kubernetes 集群中各种资源的负载不均问题。换句话说,Crane-scheduler 着力于调度层面,让集群资源使用最大化的同时排除了稳定性的后顾之忧,真正实现「降本增效」
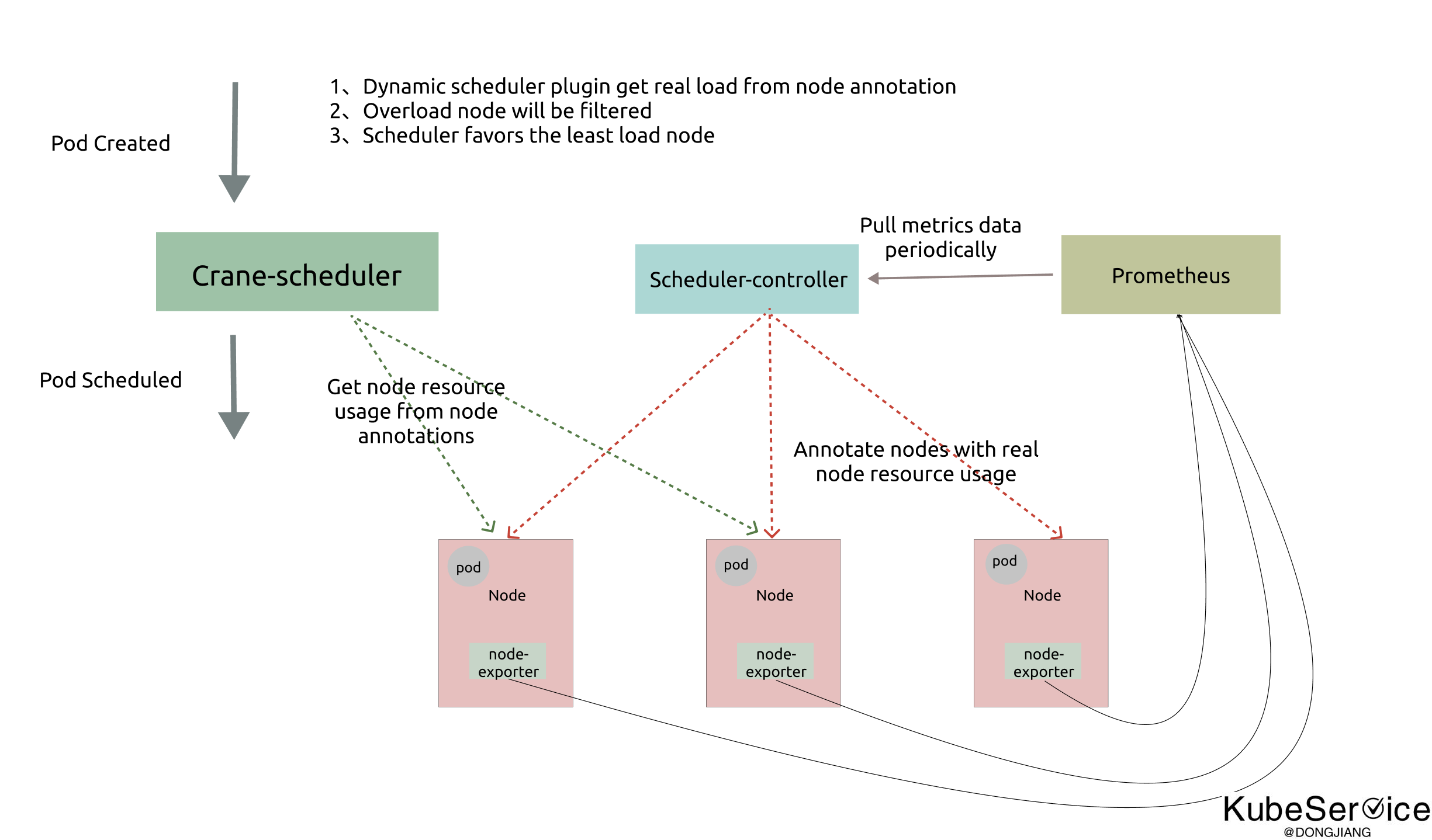
Crane-Scheduler 与社区同类型的调度器最大的区别之一:
- 前者提供了一个泛化的调度策略配置接口,给予了用户极大的灵活性;
- 后者往往只能支持 cpu/memory 等少数几种指标的感知调度,且指标聚合方式,打分策略均受限。
在 Crane-scheduler 中,用户可以为候选节点配置任意的评价指标类型(只要从 Prometheus 能拉到相关数据),不论是常用到的 CPU/Memory 使用率,还是 IO、Network Bandwidth 或者 GPU 使用率,均可以生效,并且支持相关策略的自定义配置。
2. 正式使用中的问题
问题一:当Kubernetes节点中 Node 节点过于庞大时, Prometheus资源消耗会是一个很大开销!
1000个Node节点, Prometheus基本需要 32core 64G的 至少2个 node部署HA版本; 并且还有 Prometheus 周边的一堆东西: Operator、ServiceMonitor、CRD等一堆东西
问题二:Prometheus 从旁路监控(offline系统),变成(online系统), 降低整个体系稳定性;
基于以上问题,对现有的 scheduler-controller 进行增强:
去掉Prometheus的依赖,并对node-exporter-plus进行增强,支持内存计算;直接通过 scheduler-controller 轮询方式 node-exporter-plus 并将指标添加到 node annotations
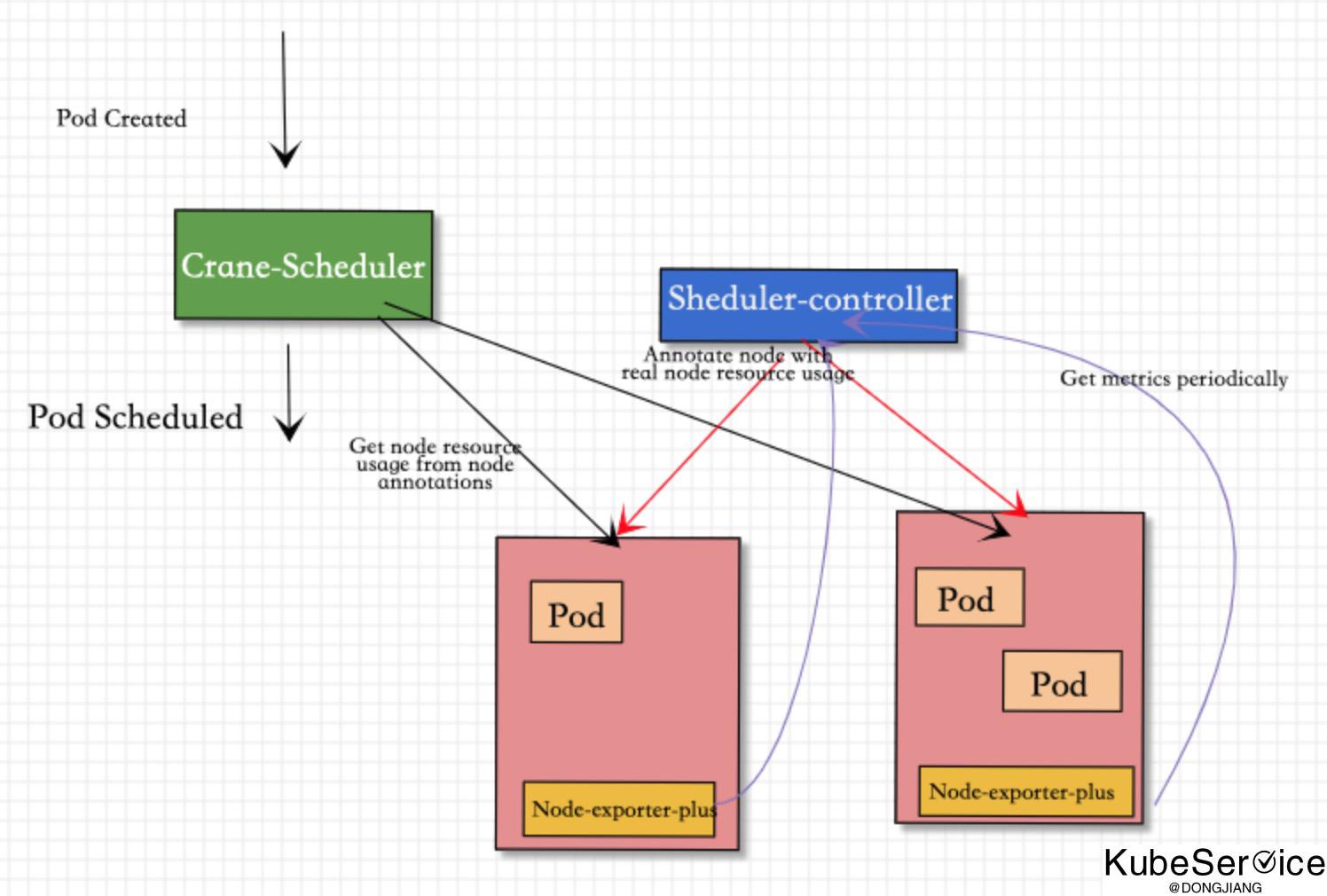
如上图所示,Crane-scheduler-plus 仅依赖 Node-exporter-plus 组件.
-
Scheduler-Controller会周期性轮训到Node-exporter-plus真实负载数据, 再以Annotation的形式标记在各个节点上; -
Scheduler则直接在从候选节点的Annotation读取负载信息,并基于这些负载信息在Filter阶段对节点进行过滤以及在Score阶段对节点进行打分; -
Node-exporter-plus会更加配置 在内存中计算好各类指标, 比如:cpu_usage_avg_5m、cpu_usage_max_avg_1h、mem_usage_avg_5m、mem_usage_max_avg_1h等,通过metrics的gauge指标方式暴露出去
基于上述架构,最终实现了基于真实负载对 Pod 进行有效调度。
并且对Scheduler-Controller过载保护:
-
- 如果通过
endpoints来访问的node节点过多, 在一个周期(比如15s)处理不完, 会保证本次处理完成后,在执行下一次, 优先一个轮回完成
- 如果通过
-
- metrics中是通过
Promethrus Gauge, 在每个周期中单独计算, 保证即使网络异常丢失 pull 请求,也可以通过下一次请求进行补足
- metrics中是通过
3. 设计方式
3.1 Scheduler-Controller 变化
将PromClient 拉取 方式变更为 ClientSet 请求 service endpoints方式 获得各个结果metrics数据
type PromClient interface {
// QueryByNodeIP queries data by node IP.
QueryByNodeIP(string, string) (string, error)
// QueryByNodeName queries data by node IP.
QueryByNodeName(string, string) (string, error)
// QueryByNodeIPWithOffset queries data by node IP with offset.
QueryByNodeIPWithOffset(string, string, string) (string, error)
}
//变更为:
type ClientSet interface {
// QueryByNodeIP queries data by node IP.
QueryByNodeIP(string, string) (string, error)
// QueryByNodeName queries data by node IP.
QueryByNodeName(string, string) (string, error)
// QueryByNodeIPWithOffset queries data by node IP with offset.
QueryByNodeIPWithOffset(string, string, string) (string, error)
// metrics 结果解析
QueryParse(string, string) (model.Vector, error)
}
3.2 Node-exporter 变化
设计 BaseCollector 实现 prometheus.GaugeValue 数据内存计算和收集
type BaseCollector struct {
metric []typedDesc
logger log.Logger
}
// NewBaseCollector returns a new Collector exposing base average stats.
func NewBaseCollector(logger log.Logger) (Collector, error) {
return &BaseCollector{
metric: []typedDesc{
{prometheus.NewDesc(namespace+"_avg_1m", "1m base average.", nil, nil), prometheus.GaugeValue},
{prometheus.NewDesc(namespace+"_avg_5m", "5m base average.", nil, nil), prometheus.GaugeValue},
{prometheus.NewDesc(namespace+"_avg_1d", "1d base average.", nil, nil), prometheus.GaugeValue},
},
logger: logger,
}, nil
}
func (c *BaseCollector) Update(ch chan<- prometheus.Metric) error {
loads, err := getData() // 实时指标
if err != nil {
return fmt.Errorf("couldn't get load: %w", err)
}
for i, load := range loads {
level.Debug(c.logger).Log("msg", "return load", "index", i, "load", load)
ch <- c.metric[i].mustNewConstMetric(load)
}
return err
}
通过配置
metrics:
- name: cpu_usage_avg_5m
period: 3m
- name: cpu_usage_max_avg_1h
period: 15m
- name: cpu_usage_max_avg_1d
period: 3h
- name: mem_usage_avg_5m
period: 3m
- name: mem_usage_max_avg_1h
period: 15m
- name: mem_usage_max_avg_1d
period: 3h
//...
4. 发布
请关注 https://github.com/kubeservice-stack/crane-scheduler
「如果这篇文章对你有用,请随意打赏」
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付
