现象
表现是:通过docker exec进入容器卡住,并且在10后 rpc timeout 报错
背景信息
docker info信息
[deployer@xxxx ~]$ sudo docker info
Containers: 47
Running: 30
Paused: 0
Stopped: 17
Images: 30
Server Version: 18.09.5
Storage Driver: overlay2
Backing Filesystem: xfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: bb71b10fd8f58240ca47fbb579b9d1028eea7c84
runc version: 2b18fe1d885ee5083ef9f0838fee39b62d653e30
init version: fec3683
Security Options:
seccomp
Profile: default
Kernel Version: 4.19.25-200.1.el7.bclinux.x86_64
Operating System: BigCloud Enterprise Linux For LDK 7 (Core)
OSType: linux
Architecture: x86_64
CPUs: 96
Total Memory: 503.3GiB
Name: xxxxxxxxxxxxxxxxxx
ID: G7IO:HPPY:SM6R:D3WJ:ETMW:OD4L:3FSH:R2FR:HHJX:S23G:PC4C:IY4P
Docker Root Dir: /apps/data/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
0.0.0.0/0
127.0.0.0/8
Live Restore Enabled: true
Product License: Community Engine
- docker version
[deployer@xxxx ~] sudo docker version
Client:
Version : 18.09.5
API version: 1.39
Go version : go1.11.5
Git commit: ded83fc
Built: Thu Apr 25 07:37:52 2019Tinux/amd64
0S/Arch:Experimental: false
Server: Docker Engine - CommunityEngine:
Version : 18.09.51.39 (minimum version 1.12)
API version: go1.10.8
Go version:
Git commit: e8ff056
Built: Thu Apr 11 04:13:40 2019
OS/Arch: Tinux/amd64
Experimental: false
- 其他疑似信息
- 疑似错误日志1
Jul 29 02:51:12 xxxxxxxxxxxxxxxxxx dockerd: time="2023-07-29T02:51:12.332760649+08:00" level=error msg="Handler for GET /v1.24/containers/fd49a3c193d6a7f7956798dbae6567d6c3589e4fed615980a6c301b51c63d71e/top returned error: ttrpc: client shutting down: ttrpc: closed: unknown"
Jul 29 02:51:12 xxxxxxxxxxxxxxxxxx dockerd: time="2023-07-29T02:51:12.332835136+08:00" level=error msg="stream copy error: reading from a closed fifo"
Jul 29 02:51:12 xxxxxxxxxxxxxxxxxx dockerd: time="2023-07-29T02:51:12.332835578+08:00" level=error msg="stream copy error: reading from a closed fifo"
Jul 29 02:51:12 xxxxxxxxxxxxxxxxxx dockerd: time="2023-07-29T02:51:12.332953620+08:00" level=error msg="Error running exec 32acca65977de1f1a5c0481bc40cfc6c1819c1238e7015cbe9e6240c681742c4 in container: ttrpc: client shutting down: ttrpc: closed: unknown"
Jul 29 02:51:12 xxxxxxxxxxxxxxxxxx kubelet: W0729 02:51:12.333314 237304 prober.go:108] No ref for container "docker://fd49a3c193d6a7f7956798dbae6567d6c3589e4fed615980a6c301b51c63d71e" (af3fcc9725d-a5ed100-0_qfusion-admin(8c6a2f90-b80e-409f-871c-2e2a80732cf7):mysql)
Jul 29 02:51:12 xxxxxxxxxxxxxxxxxx kubelet: I0729 02:51:12.333327 237304 prober.go:116] Readiness probe for "af3fcc9725d-a5ed100-0_qfusion-admin(8c6a2f90-b80e-409f-871c-2e2a80732cf7):mysql" failed (failure): ttrpc: client shutting down: ttrpc: closed: unknown
- 疑似错误日志2
Jul 29 02:57:15 xxxxxxxxxxxxxxxxxx kubelet: E0729 02:57:15.323471 237304 remote_runtime.go:351] ExecSync fd49a3c193d6a7f7956798dbae6567d6c3589e4fed615980a6c301b51c63d71e '/usr/local/bin/mysql/mysqlprobe' from runtime service failed: rpc error: code = Unknown desc = operation timeout: context deadline exceeded
Jul 29 02:57:15 xxxxxxxxxxxxxxxxxx kubelet: W0729 02:57:15.323520 237304 prober.go:108] No ref for container "docker://fd49a3c193d6a7f7956798dbae6567d6c3589e4fed615980a6c301b51c63d71e" (af3fcc9725d-a5ed100-0_qfusion-admin(8c6a2f90-b80e-409f-871c-2e2a80732cf7):mysql)
Jul 29 02:57:15 xxxxxxxxxxxxxxxxxx kubelet: I0729 02:57:15.323528 237304 prober.go:111] Readiness probe for "af3fcc9725d-a5ed100-0_qfusion-admin(8c6a2f90-b80e-409f-871c-2e2a80732cf7):mysql" errored: rpc error: code = Unknown desc = operation timeout: context deadline exceeded
- 疑似错误日志3
Jul 29 03:03:15 xxxxxxxxxxxxxxxxxx kubelet: E0729 03:03:15.324517 237304 remote_runtime.go:351] ExecSync fd49a3c193d6a7f7956798dbae6567d6c3589e4fed615980a6c301b51c63d71e '/usr/local/bin/mysql/mysqlprobe' from runtime service failed: rpc error: code = Unknown desc = operation timeout: context deadline exceeded
Jul 29 03:03:15 xxxxxxxxxxxxxxxxxx kubelet: W0729 03:03:15.324563 237304 prober.go:108] No ref for container "docker://fd49a3c193d6a7f7956798dbae6567d6c3589e4fed615980a6c301b51c63d71e" (af3fcc9725d-a5ed100-0_qfusion-admin(8c6a2f90-b80e-409f-871c-2e2a80732cf7):mysql)
Jul 29 03:03:15 xxxxxxxxxxxxxxxxxx kubelet: I0729 03:03:15.324573 237304 prober.go:111] Readiness probe for "af3fcc9725d-a5ed100-0_qfusion-admin(8c6a2f90-b80e-409f-871c-2e2a80732cf7):mysql" errored: rpc error: code = Unknown desc = operation timeout: context deadline exceeded
- 疑似错误日志4
Jul 29 09:51:50 xxxxxxxxxxxxxxxxxx kubelet: E0729 09:51:50.992478 237304 remote_runtime.go:295] ContainerStatus "fd49a3c193d6a7f7956798dbae6567d6c3589e4fed615980a6c301b51c63d71e" from runtime service failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 29 09:51:50 xxxxxxxxxxxxxxxxxx kubelet: E0729 09:51:50.992529 237304 kuberuntime_manager.go:935] getPodContainerStatuses for pod "af3fcc9725d-a5ed100-0_qfusion-admin(8c6a2f90-b80e-409f-871c-2e2a80732cf7)" failed: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Jul 29 09:51:51 xxxxxxxxxxxxxxxxxx systemd: Started Session c8537794 of user root.
Jul 29 09:51:53 xxxxxxxxxxxxxxxxxx kubelet: E0729 09:51:53.186201 237304 kubelet_pods.go:1093] Failed killing the pod "af3fcc9725d-a5ed100-0": failed to "KillContainer" for "mysql" with KillContainerError: "rpc error: code = DeadlineExceeded desc = context deadline exceeded"
Jul 29 09:51:55 xxxxxxxxxxxxxxxxxx kubelet: I0729 09:51:55.185431 237304 kubelet_pods.go:1090] Killing unwanted pod "af3fcc9725d-a5ed100-0"
Jul 29 09:54:52 xxxxxxxxxxxxxxxxxx kubelet: I0729 09:54:52.876593 237304 kubelet.go:1839] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m0.883911016s ago; threshold is 3m0s
Jul 29 09:54:53 xxxxxxxxxxxxxxxxxx kubelet: I0729 09:54:53.676724 237304 kubelet.go:1839] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m1.684040284s ago; threshold is 3m0s
Jul 29 09:54:55 xxxxxxxxxxxxxxxxxx kubelet: I0729 09:54:55.276865 237304 kubelet.go:1839] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m3.284184331s ago; threshold is 3m0s
Jul 29 09:54:58 xxxxxxxxxxxxxxxxxx kubelet: I0729 09:54:58.476993 237304 kubelet.go:1839] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m6.484309601s ago; threshold is 3m0s
Jul 29 09:55:00 xxxxxxxxxxxxxxxxxx kubelet: I0729 09:55:00.197393 237304 setters.go:73] Using node IP: "10.191.56.152"
Jul 29 09:55:00 xxxxxxxxxxxxxxxxxx kubelet: I0729 09:55:00.198789 237304 kubelet_node_status.go:472] Recording NodeNotReady event message for node cqst-psc-p12f6-spod2-pm-os1-mysql-lk8s152
Jul 29 09:55:00 xxxxxxxxxxxxxxxxxx kubelet: I0729 09:55:00.198813 237304 setters.go:539] Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2023-07-29 09:55:00.198769967 +0800 CST m=+5526333.450288300 LastTransitionTime:2023-07-29 09:55:00.198769967 +0800 CST m=+5526333.450288300 Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m8.206109901s ago; threshold is 3m0s}
- 问题5
Jul 29 12:01:51 xxxxxxxxxxxxxxxxxx systemd: Started Session c8539902 of user root.
Jul 29 12:01:53 xxxxxxxxxxxxxxxxxx dockerd: time="2023-07-29T12:01:53.398952203+08:00" level=error msg="stream copy error: reading from a closed fifo"
Jul 29 12:01:53 xxxxxxxxxxxxxxxxxx dockerd: time="2023-07-29T12:01:53.443504033+08:00" level=error msg="Error running exec c10aac06ab0725a541bd1f27ea7dad68d35b639ec6f75d6ec38c4c0aa311e526 in container: OCI runtime exec failed: exec failed: container_linux.go:345: starting container process caused \"exec: \\\"--\\\": executable file not found in $PATH\": unknown"
问题追查
首先怀疑: docker bug
目前所有的错误请求都是 af3fcc9725d-a5ed100-0 pod的Readiness probe出错开始,Error包括有 probe rpc operation timeout 、rpc: client shutting down.
查看底层代码: https://github.com/containerd/ttrpc/blob/main/client.go#L279-L307
// Close closes the ttrpc connection and underlying connection
func (c *Client) Close() error {
c.closeOnce.Do(func() {
c.closed()
c.conn.Close()
})
return nil
}
// UserOnCloseWait is used to blocks untils the user's on-close callback
// finishes.
func (c *Client) UserOnCloseWait(ctx context.Context) error {
select {
case <-c.userCloseWaitCh:
return nil
case <-ctx.Done():
return ctx.Err()
}
}
func (c *Client) run() {
err := c.receiveLoop()
c.Close()
c.cleanupStreams(err)
c.userCloseFunc()
close(c.userCloseWaitCh)
}
是Readiness probe中长连接请求,被关闭(连接终端)导致底层 Probe请求出错。
但是非稳定出现。如果按probe也是设置,连续3次 readiness probe失败,kubelet就会重启此pod。 从日志中看,每10分钟左右,出现一次
再查看整个node上的资源情况: 10个pod, 16个container pod非常少。并且其他 pod 的执行等也有readiness和liveines (比如cni). 但错误只是集中此一个pod上.
然而,此不是docker问题。
其次是否是rootfs问题: executable file not found 和 unmount task rootfs
对于caused \"exec: \\\"--\\\": executable file not found in $PATH\": unknown是使用者,手工输入错错误信息导致
复现步骤
[deployer@xxxx ~]$ sudo docker exec -it xxxx -- bash
OCI runtime exec failed: exec failed: container_linux.go:345: starting container process caused "exec: \"--\": executable file not found in PATH: unknown
是运维同学混淆了kubectl exec -it <podid> -- bash 和 docker exec -it <containerid> bash/sh 用法导致。日志是正常出现的错误日志
unmount task rootfs 是一个问题容器想更新KillContainer pod, 但是kill不掉,是warning整体不影响。
PLEG is not healthy 导致 Node NotReady
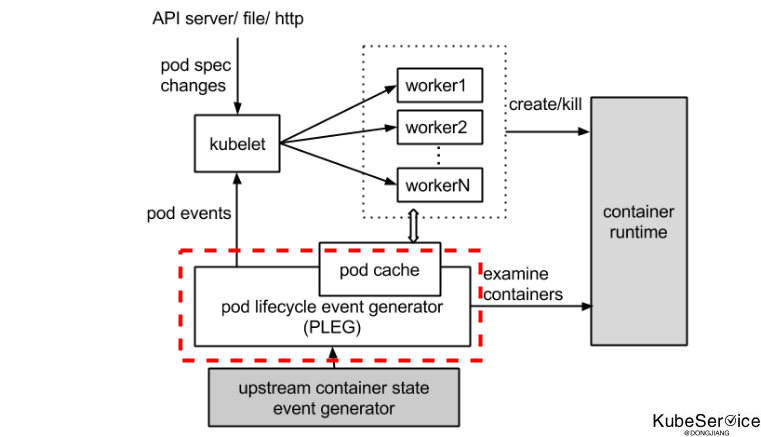
PLEG 在kubelet内部中,维护了一个plegChannelCapacity, 处理循环执行pod 的 docker ps 和 docker inspect 查询容器状态, 保持最新的podstatus.
如果relistThreshold过程花费超过 3分钟,则会通过堆栈过程报告PLEG is not healthy问题。 plegRelistPeriod relist过程没间隔1s 进行执行。
plegChannelCapacity = 1000 // 1000个channel维护 pleg问题
plegRelistPeriod = time.Second * 1 // 每1s执行一次relist
relistThreshold = 3 * time.Minute // relist超时时间为3min
PLEG is not healthy 因素: relist code
以个人经验,造成 ·PLEG is not healthy· 的因素有很多,社区有很多PLEG的issue问题, 级别上都没有解决:
- RPC 调用过程中容器运行时响应超时(runtime异常,所有的pod都有超时/变慢);
- 节点上的
Pod 数量太多,导致relist无法在 3 分钟内完成。事件数量和延时与Pod 数量成正比,与节点资源无关; - relist 出现了死锁,该 bug 已在 Kubernetes 1.14 中修复;
- 获取 Pod 的网络堆栈信息时 CNI 出现了 bug;
对于目前问题,10个pod, 16个container pod非常少, 不符合第二点; 并且所有的PLEG都出现一个pod(af3fcc9725d-a5ed100-0)上, 并非底层runtime问题, 也不符合第二个问题;
无CNI错误和 kubernete版本1.18,其他两个点也不符合。
Node NotReady问题
Node became not ready: {Type:Ready Status:False LastHeartbeatTime:2023-07-29 09:42:49.567539063 +0800 CST m=+5525602.819057397 LastTransitionTime:2023-07-29 09:42:49.567539063 +0800 CST m=+5525602.819057397 Reason:KubeletNotReady Message:PLEG is not healthy: pleg was last seen active 3m0.648158806s ago; threshold is 3m0s}
由于 此一个 pod hang 导致, 3min内无响应,导致Node NotReady. 当时check 其他pod(cni、fluted) status,又将pleg状态更新,设置node ready
问题处理
清理到 hang 住的pod下的container
- 强制删除 Pod
kubectl -n <命名空间> delete pod --force --grace-period=0 xxx
- 强制删除容器
对于日志报 KillContainerError 错误的,可以根据日志的提示,在主机上执行 docker ps -a | grep <Pod 名称> 来查询容器 ID,然后通过 docker rm -f <容器 id> 来删除容器。
- 通过
Pid删除容器
有时候在第 2 步中执行 docker rm -f <容器 id> 删除容器 时没有任何响应,这种情况可以通过 KILL PID 的方式来删除容器。
其他:
https://developers.redhat.com/blog/2019/11/13/pod-lifecycle-event-generator-understanding-the-pleg-is-not-healthy-issue-in-kubernetes https://github.com/kubernetes/kubernetes/issues/61117 https://github.com/kubernetes/kubernetes/issues/101056 https://www.xtplayer.cn/kubernetes/kubelet/pleg-is-not-healthy-2/#PLEG-is-not-healthy-%E5%88%86%E6%9E%90
「如果这篇文章对你有用,请随意打赏」
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付
