golang 实现交替加权轮询-interleaved weighted round robin
背景
背景实现: O(1) 时间复杂度 和 O(n) 空间复杂度 的 加权负载平衡实现
交错式加权轮询负载均衡算法 interleaved weighted round robin (iwrr) 是 时间复杂度O(1),空间复杂度O(n),相比于VNSWRR的O(sigma(W))更省空间且可控
算法如下: https://en.wikipedia.org/wiki/Weighted_round_robin#Interleaved_WRR
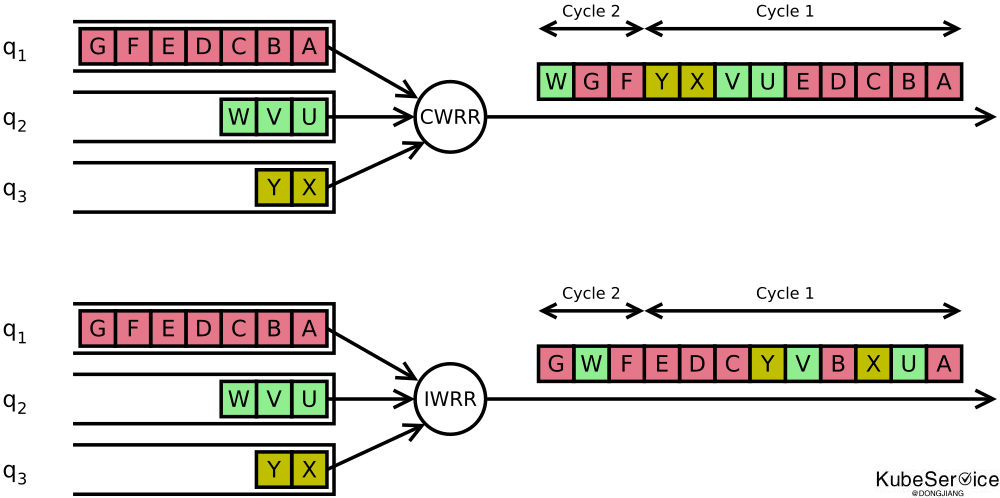
除了性能提升外,也解决小请求、小queue中的请求长期饥饿的问题;
实现说明
与Linux O(1)调度器思路相同:
-
实现中维护
两个队列,分别是当前队列current queue和下一次队列next queue。队列中的每个元素entry都维护weight表示在当前队列中任选中次数权重. -
最初时
weight与entry权重相同,每次被选中后都会减少step(使用GCD公约数来调整个周期)。 -
当
weight为0时表示当前周期内不可调度,将其放在下一次队列中。当当前队列current queue为empty时, 表示当前周期所有元素entry都被按权重选择结束,此时对换当前队列和下一次队列开始新的周期。 -
由于始终
重复用链表节点,因此该负载均衡算法在初始化后实现可以保证是zero-copy的。
实现
package iwrr
import (
"math/rand"
"sync"
"dubbo.apache.org/dubbo-go/v3/cluster/loadbalance"
"dubbo.apache.org/dubbo-go/v3/protocol"
)
type iwrrEntry struct {
weight int64
invoker protocol.Invoker
next *iwrrEntry
}
type iwrrQueue struct {
head *iwrrEntry
tail *iwrrEntry
}
func NewIwrrQueue() *iwrrQueue {
return &iwrrQueue{}
}
func (item *iwrrQueue) push(entry *iwrrEntry) {
entry.next = nil
tail := item.tail
item.tail = entry
if tail == nil {
item.head = entry
} else {
tail.next = entry
}
}
func (item *iwrrQueue) pop() *iwrrEntry {
head := item.head
next := head.next
head.next = nil
item.head = next
if next == nil {
item.tail = nil
}
return head
}
func (item *iwrrQueue) empty() bool {
return item.head == nil
}
// InterleavedweightedRoundRobin struct
type interleavedweightedRoundRobin struct {
current *iwrrQueue
next *iwrrQueue
step int64
mu sync.Mutex
}
func NewInterleavedweightedRoundRobin(invokers []protocol.Invoker, invocation protocol.Invocation) *interleavedweightedRoundRobin {
iwrrp := new(interleavedweightedRoundRobin)
iwrrp.current = NewIwrrQueue()
iwrrp.next = NewIwrrQueue()
size := uint64(len(invokers))
offset := rand.Uint64() % size
step := int64(0)
for idx := uint64(0); idx < size; idx++ {
invoker := invokers[(idx+offset)%size]
weight := loadbalance.GetWeight(invoker, invocation)
step = gcdInt(step, weight)
iwrrp.current.push(&iwrrEntry{
invoker: invoker,
weight: weight,
})
}
iwrrp.step = step
return iwrrp
}
func (iwrr *interleavedweightedRoundRobin) Pick(invocation protocol.Invocation) protocol.Invoker {
iwrr.mu.Lock()
defer iwrr.mu.Unlock()
if iwrr.current.empty() {
iwrr.current, iwrr.next = iwrr.next, iwrr.current
}
entry := iwrr.current.pop()
entry.weight -= iwrr.step
if entry.weight > 0 {
iwrr.current.push(entry)
} else {
weight := loadbalance.GetWeight(entry.invoker, invocation)
if weight < 0 {
weight = 0
}
entry.weight = weight
iwrr.next.push(entry)
}
return entry.invoker
}
func gcdInt(a, b int64) int64 {
for b != 0 {
a, b = b, a%b
}
return a
}
dubbo-go各loadbalance性能对比
goos: darwin
goarch: amd64
pkg: dubbo.apache.org/dubbo-go/v3/cluster/loadbalance
cpu: VirtualApple @ 2.50GHz
BenchmarkRoudrobinLoadbalace-8 6739 157254 ns/op 88101 B/op 2555 allocs/op
BenchmarkLeastativeLoadbalace-8 7248 153721 ns/op 81877 B/op 2043 allocs/op
BenchmarkConsistenthashingLoadbalace-8 57810 20709 ns/op 3425 B/op 267 allocs/op
BenchmarkP2CLoadbalace-8 2716834 445.1 ns/op 456 B/op 10 allocs/op
BenchmarkInterleavedWeightedRoundRobinLoadbalace-8 20829 57722 ns/op 45296 B/op 1027 allocs/op
BenchmarkRandomLoadbalace-8 23924 49694 ns/op 38976 B/op 767 allocs/op
PASS
ok dubbo.apache.org/dubbo-go/v3/cluster/loadbalance 10.348s
对比原生的wrr, iwrr的性能是wrr的3x+. 内存使用只有wrr不到一半
其他
「如果这篇文章对你有用,请随意打赏」
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付
