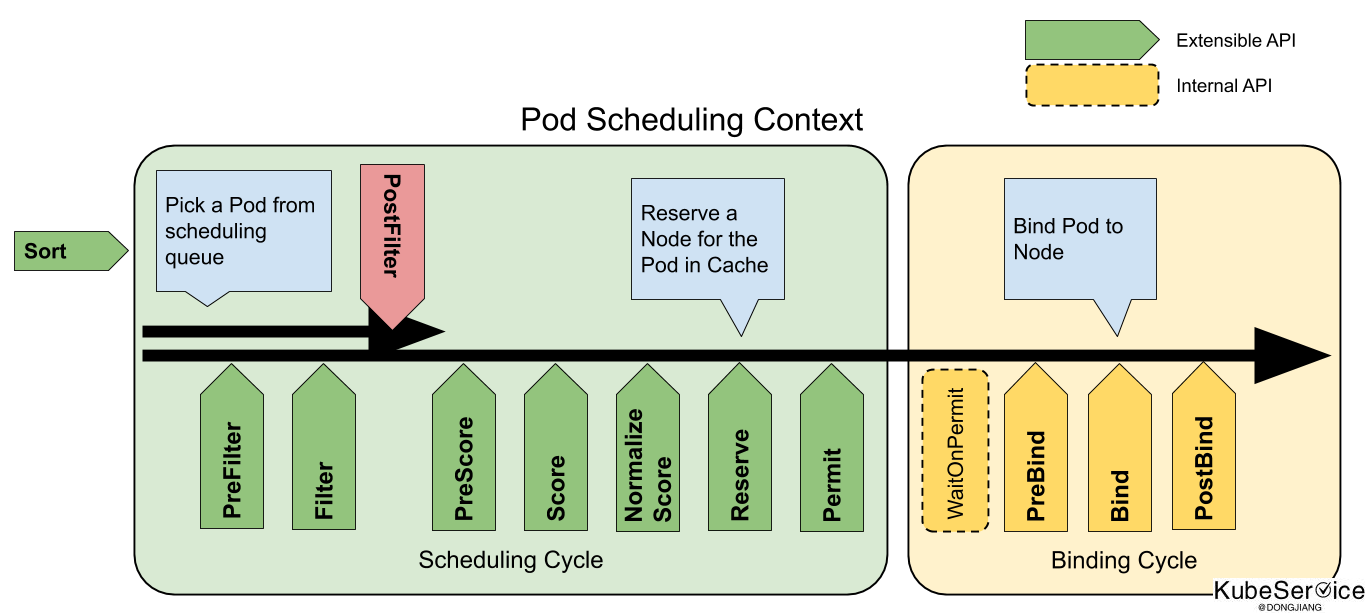
Kubernetes descheduler使用方式
descheduler是对于现有的 kube-scheduler 精细化调度丰富. de-scheduler 当业务长期运行后, 出现warning到一定情况,通过预先设置的自动干预法策略,来重新调度资源。
主要是丰富了: 掉漆中Filter、strategy环节中,实现插件middleware功能。从而影响调度决策。
descheduler架构
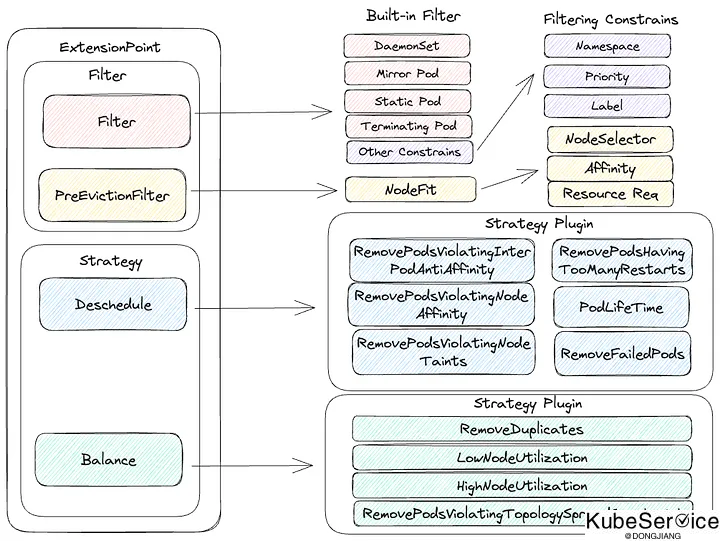
Descheduler的配置主要由Policies组成. Policies由Evictor和Strategies组成。
策略决定在什么情况下应该重新分配 Pod,而 Evictor 则确定哪些 Pod 有资格重新分配.
Evictor 驱逐者
Evictor 目前采用两种内置机制,即 Filter 和 PreEvicitionFilter 两套interface接口插件。
其中 Filter 默认放通以下pod. 有些特殊的pod,是不是被descheduler调度的. 包括:
- Static pods
- DaemonSet Pods
- Terminating Pods
- Success Pods
- 满足特定命名空间/优先级/标签条件的 Pod
还有:
- 具有本地存储的 Pod 永远不会被驱逐
- 带有 PVC 的 Pod 会被驱逐
- 带有 PDB 的 Pod 会被驱逐(利用齐本身的PDB做驱逐)
而,PreEvicitionFilter 会检查 Pod 的 NodeSelector/Affinity/Taint/Request 是否有可用于重新部署的节点。
Strategies 策略
Strategy 内置两种策略:取消计划Remove和资源均衡Balance。
| 名称 | 已实现的扩展点 | 说明 |
|---|---|---|
| RemoveDuplicates | 余额 | 传播副本 |
| LowNodeUtilization | Balance | 根据 Pod 资源请求和可用节点资源分散 Pod |
| HighNodeUtilization | Balance | 根据 Pod 资源请求和可用节点资源分散 Pod |
| RemovePodsViolatingInterPodAntiAffinity | 取消计划 | 驱逐违反 Pod 反亲和力的 Pod |
| RemovePodsViolatingNodeAffinity | 取消计划 | 驱逐违反节点亲和力的 Pod |
| RemovePodsViolatingNodeTaints | 取消计划 | 驱逐违反节点污点的 Pod |
| RemovePodsViolatingTopologySpreadConstraint | 平衡 | 驱逐违反 TopologySpreadConstraints 的 Pod |
| RemovePodsHavingTooManyRestarts | 取消计划 | 驱逐重启次数过多的 Pod |
| PodLifeTime | 取消计划 | 驱逐超过指定年龄限制的 Pod |
| RemoveFailedPods | 取消计划 | 因某些失败原因驱逐 Pod |
具体策略介绍
建议使用:发现pod不知原因的N多次重启,将此pod驱逐到其他机器上
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "RemovePodsHavingTooManyRestarts"
args:
podRestartThreshold: 50 # 重启次数高达50次以上
includingInitContainers: true # 是否check InitContainer的重启次数
states:
- CrashLoopBackOff
plugins:
deschedule:
enabled:
- "RemovePodsHavingTooManyRestarts"
建议使用: 确保只有一个 pod 与在同一节点上运行, 删除重复Pod主动驱逐
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "RemoveDuplicates"
args:
excludeOwnerKinds: # ReplicationController/ReplicaSet/StatefulSet/Job
- "ReplicaSet"
- "ReplicationController"
namespaces: # namespaces 白名单和黑名单
include:
- "namespace1"
- "namespace2"
exclude:
- "namespace3"
- "namespace4"
plugins:
balance:
enabled:
- "RemoveDuplicates"
谨慎使用: 查找未充分利用的节点,并在可能的情况下从其他节点逐出 pod
PS: 依赖metrice-server Node利用率资源
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "LowNodeUtilization"
args:
useDeviationThresholds: true # 如果设置为true, 是集群平均资源的偏差值;如果为false, 是节点node绝对值百分比;
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
targetThresholds:
"cpu" : 50
"memory": 50
"pods": 50
numberOfNodes: 5 # 仅当未充分利用的节点数高于5时, 才激活该策略
evictableNamespaces: # namespaces 白名单和黑名单
include:
- "namespace1"
- "namespace2"
exclude:
- "kube-system"
plugins:
balance:
enabled:
- "LowNodeUtilization"
不建议使用: 找到未充分利用的节点,并将 pod 从节点中逐出,将 pod 紧凑地调度到更少利用率的节点
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "HighNodeUtilization"
args:
numberOfNodes: 5 # 仅当未充分利用的节点数高于5时, 才激活该策略
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
evictableNamespaces: # namespaces 白名单和黑名单
exclude:
- "kube-system"
- "namespace1"
include:
- "namespace2"
- "namespace3"
plugins:
balance:
enabled:
- "HighNodeUtilization"
不建议使用: 删除违反 Pod 间反亲和性的 Pod(PodA、PodB有亲和性,会祸及 PodC)
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "RemovePodsViolatingInterPodAntiAffinity"
args:
numberOfNodes: 5 # 仅当未充分利用的节点数高于5时, 才激活该策略
labelSelector:
matchLabels: # label match
component: xxxx
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]}
namespaces: # namespaces 白名单和黑名单
exclude:
- "kube-system"
- "namespace1"
include:
- "namespace2"
- "namespace3"
plugins:
deschedule:
enabled:
- "RemovePodsViolatingInterPodAntiAffinity"
谨慎使用: 删除节点上违反 NoSchedule 污点的 Pod,将有NoSchedule的Node排除考虑调度之外
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "RemovePodsViolatingNodeTaints"
args:
excludedTaints:
- key1=value1 # 剔除 taints 包含 key "key1" and value "value1"
- reserved # 剔除所有 taints 包含 key "reserved"
namespaces: # namespaces 白名单和黑名单
exclude:
- "kube-system"
- "namespace1"
include:
- "namespace2"
- "namespace3"
plugins:
deschedule:
enabled:
- "RemovePodsViolatingNodeTaints"
不建议使用: Pod提前驱逐,早于 的 pod maxPodLifeTimeSeconds进行驱逐
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "PodLifeTime"
args:
maxPodLifeTimeSeconds: 86400
states:
- "Pending"
- "PodInitializing"
labelSelector:
matchLabels: # label match
component: xxxx
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]}
namespaces: # namespaces 白名单和黑名单
exclude:
- "kube-system"
- "namespace1"
include:
- "namespace2"
- "namespace3"
plugins:
deschedule:
enabled:
- "PodLifeTime"
建议使用: 驱逐处于失败状态阶段的 Pod
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- name: "RemoveFailedPods"
args:
reasons: # 错位原因
- "NodeAffinity"
- "CrashLoopBackOff"
includingInitContainers: true # 也需要check InitContainers的错误原因
excludeOwnerKinds: # 过滤类型,Job类型Pod不考虑
- "Job"
minPodLifetimeSeconds: 360 # 逐出错位指定秒数的 Pod,单位秒
labelSelector:
matchLabels: # label match
component: xxxx
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]}
namespaces: # namespaces 白名单和黑名单
exclude:
- "kube-system"
- "namespace1"
include:
- "namespace2"
- "namespace3"
plugins:
deschedule:
enabled:
- "RemoveFailedPods"
使用和部署
descheduler 本身支持两个部署模式CronJob和Deployment.
- CronJob是通过cron schedule定时扫描各种policy rule,定时调度
- Deployment是实现
schedule controllerwatch了Node/Namespace/Pod/PriorityClass进行执行;
下载helm package, 并且部署
地址: helm-default/charts/descheduler
$ git clone git@github.com:dongjiang1989/descheduler.git
$ git checkout helm-default
$ cd ./charts/descheduler/
$ helm install descheduler --namespace=kube-system .
NAME: descheduler
LAST DEPLOYED: Fri Dec 8 10:49:29 2023
NAMESPACE: kube-system
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Descheduler installed as a Deployment.
$ helm list -n kube-system
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
descheduler kube-system 1 2023-12-08 10:49:29.879648 +0800 CST deployed descheduler-1.0.0 v1.0.0
验证
实例情况,deployment模式,3副本,1个leadeer:
$ kubectl get pod -n kube-system | grep descheduler
descheduler-585b7db478-55cw2 1/1 Running 0 2m16s
descheduler-585b7db478-7xzrd 1/1 Running 0 2m16s
descheduler-585b7db478-nk4nl 1/1 Running 0 2m16s
CRD 数据:
$ kubectl describe cm descheduler -n kube-system
Name: descheduler
Namespace: kube-system
Labels: app.kubernetes.io/instance=descheduler
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=descheduler
app.kubernetes.io/version=v1.0.0
helm.sh/chart=descheduler-1.0.0
Annotations: meta.helm.sh/release-name: descheduler
meta.helm.sh/release-namespace: kube-system
Data
====
policy.yaml:
----
apiVersion: "descheduler/v1alpha2"
kind: "DeschedulerPolicy"
profiles:
- name: ProfileName
pluginConfig:
- args:
excludeOwnerKinds:
- StatefulSet
- Job
namespaces:
exclude:
- kube-system
- kube-public
- kube-node-lease
name: RemoveDuplicates
- args:
evictableNamespaces:
exclude:
- kube-system
- kube-public
- kube-node-lease
targetThresholds:
cpu: 50
memory: 50
pods: 50
thresholds:
cpu: 20
memory: 20
pods: 20
name: LowNodeUtilization
- args:
includingInitContainers: true
podRestartThreshold: 50
name: RemovePodsHavingTooManyRestarts
- args:
excludeOwnerKinds:
- Job
includingInitContainers: true
minPodLifetimeSeconds: 3600
namespaces:
exclude:
- kube-system
- kube-public
- kube-node-lease
reasons:
- NodeAffinity
- CreateContainerConfigError
- OutOfcpu
name: RemoveFailedPods
plugins:
balance:
enabled:
- RemoveDuplicates
- LowNodeUtilization
deschedule:
enabled:
- RemovePodsHavingTooManyRestarts
- RemoveFailedPods
BinaryData
====
Events: <none>
压力测试 和 重启测试
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox-deployment
labels:
app: busybox
spec:
replicas: 3
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox
image: docker.io/busybox:latest
command: ['sleep', '360']
具体是否被再调度. 由于restart错误出现50次了,但是由于集群规模自由1个 work节点,因此不能被调度到其他节点;
I1208 02:52:02.726111 1 reflector.go:325] Listing and watching *v1.Namespace from k8s.io/client-go/informers/factory.go:150
I1208 02:52:02.725963 1 reflector.go:289] Starting reflector *v1.PriorityClass (0s) from k8s.io/client-go/informers/factory.go:150
I1208 02:52:02.726250 1 reflector.go:325] Listing and watching *v1.PriorityClass from k8s.io/client-go/informers/factory.go:150
I1208 02:52:02.826268 1 shared_informer.go:341] caches populated
I1208 02:52:02.826307 1 shared_informer.go:341] caches populated
I1208 02:52:02.826315 1 shared_informer.go:341] caches populated
I1208 02:52:02.826320 1 shared_informer.go:341] caches populated
I1208 02:52:02.827135 1 descheduler.go:120] "The cluster size is 0 or 1 meaning eviction causes service disruption or degradation. So aborting.."
E1208 02:52:02.827512 1 descheduler.go:430] the cluster size is 0 or 1
其他
「如果这篇文章对你有用,请随意打赏」
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付
