Kubernetes GPU share 能力
GPU 软隔离模式
通过 gpu-monitoring-tools 还获得 gpu device 驱动,并通过 deviceplugin 向kubelet注册GPU信息。
底层通过 NVIDIA docker-smi 可对容器进行gpu分配
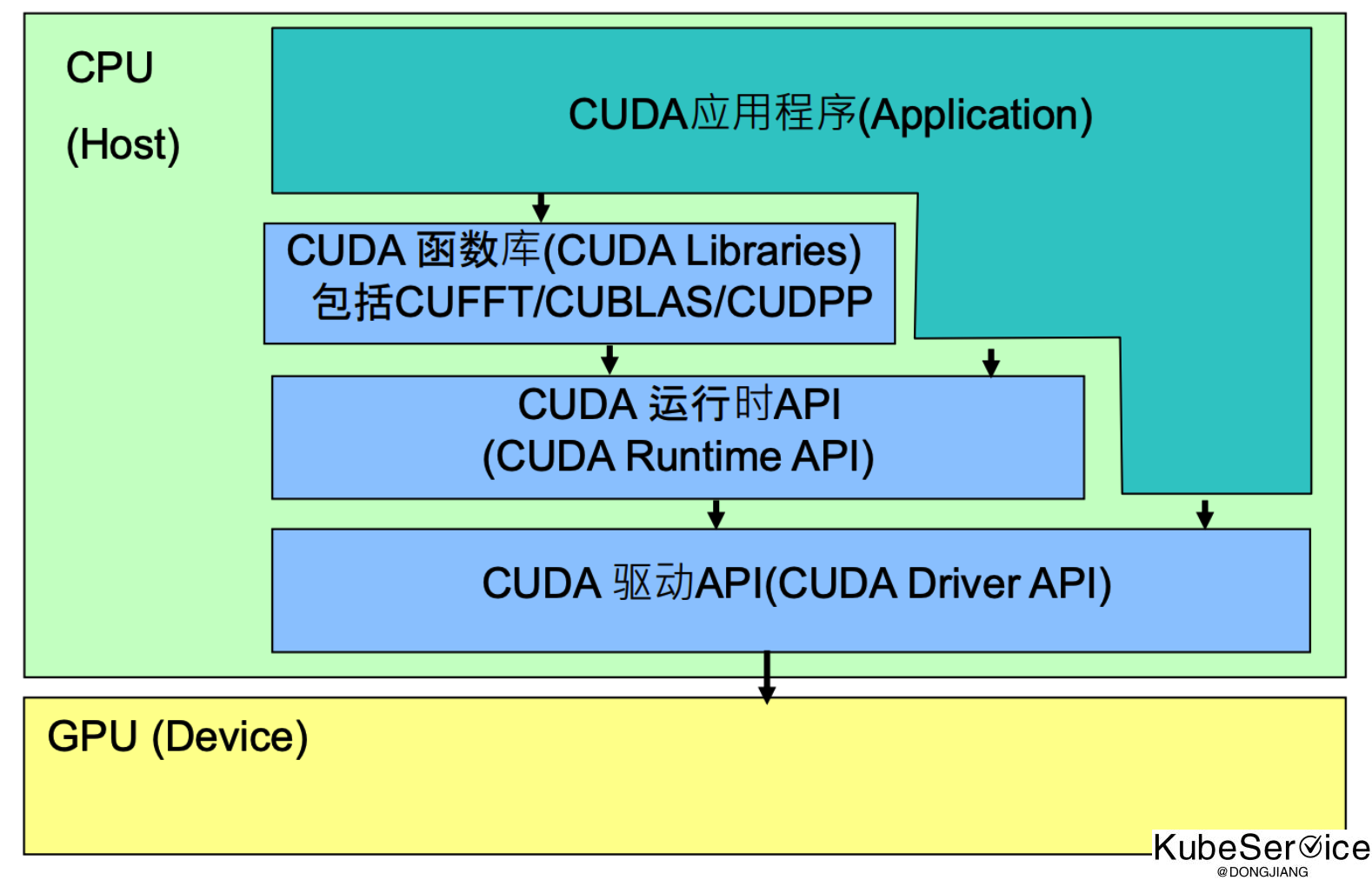
**GPU虚拟化技术: **
核心就是 上报给kubelet注册GPU信息的 deviceid 是一个虚拟的id。 当pod申请gpu是,通过本地文件维护的mapping关系,并通过allocate()后,转换实际deviceid.
GPU MPS(Multi-Process Service)
MPS(Multi-Process Service),多进程服务。一组可替换的,二进制兼容的CUDA API实现,包括三部分: 守护进程 、服务进程 、用户运行时。
MPS 利用GPU上的 Hyper-Q 能力:
- 允许多个CPU进程共享同一
GPU context - 允许不同进程的kernel和memcpy操作在同一
GPU上并发执行,以实现最大化GPU利用率
验证 GPU 状态
# nvidia-smi
Thu Dec 07 09:36:05 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.57 Driver Version: 450.57 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:1A:00.0 Off | N/A |
| 29% 56C P0 26W / 250W | 2639MiB / 12066MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla T4 Off | 00000000:1B:00.0 Off | N/A |
| 28% 56C P0 26W / 250W | 779MiB / 12066MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 159584 C ./bin/main 2635MiB |
| 0 N/A N/A 41728 C python 4MiB |
| 1 N/A N/A 152095 C ./bin/main 605MiB |
| 1 N/A N/A 3148 C python3.6 87MiB |
| 1 N/A N/A 11020 C python3.6 87MiB |
+-----------------------------------------------------------------------------+
说明一下: 第二个表中
GPU表示跑在哪一块GPU上(物理GPU的进程);Type中C表示计算,G表示图形处理; 如果是M+C就是开启MPS能力
测试验证
业界:ai-benchmark
apiVersion: batch/v1
kind: Job
metadata:
name: ai-benchmark
spec:
template:
metadata:
name: ai-benchmark
spec:
containers:
- name: ai-benchmark
image: 4pdosc/ai-benchmark:2.4.1-gpu
resources:
requests:
nvidia.com/gpu: 1 # requesting 1 vGPUs
nvidia.com/gpucores: 30 # Each vGPU uses 30% of the entire GPU
nvidia.com/gpumem: 3000 # Each vGPU contains 3000m device memory
limits:
nvidia.com/gpu: 1 # requesting 1 vGPUs
nvidia.com/gpucores: 30 # Each vGPU uses 30% of the entire GPU
nvidia.com/gpumem: 3000 # Each vGPU contains 3000m device memory
restartPolicy: Never
---
apiVersion: batch/v1
kind: Job
metadata:
name: ai-benchmark-2
spec:
template:
metadata:
name: ai-benchmark-2
spec:
containers:
- name: ai-benchmark-2
image: 4pdosc/ai-benchmark:2.4.1-gpu
resources:
requests:
nvidia.com/gpu: 1
nvidia.com/gpumem-percentage: 50
nvidia.com/gpumem: 3000 # Each vGPU contains 3000m device memory
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem-percentage: 50
nvidia.com/gpumem: 3000 # Each vGPU contains 3000m device memory
restartPolicy: Never
通过脚本nvidia-smi -l 1 每秒打印一次,查看结果。
PS
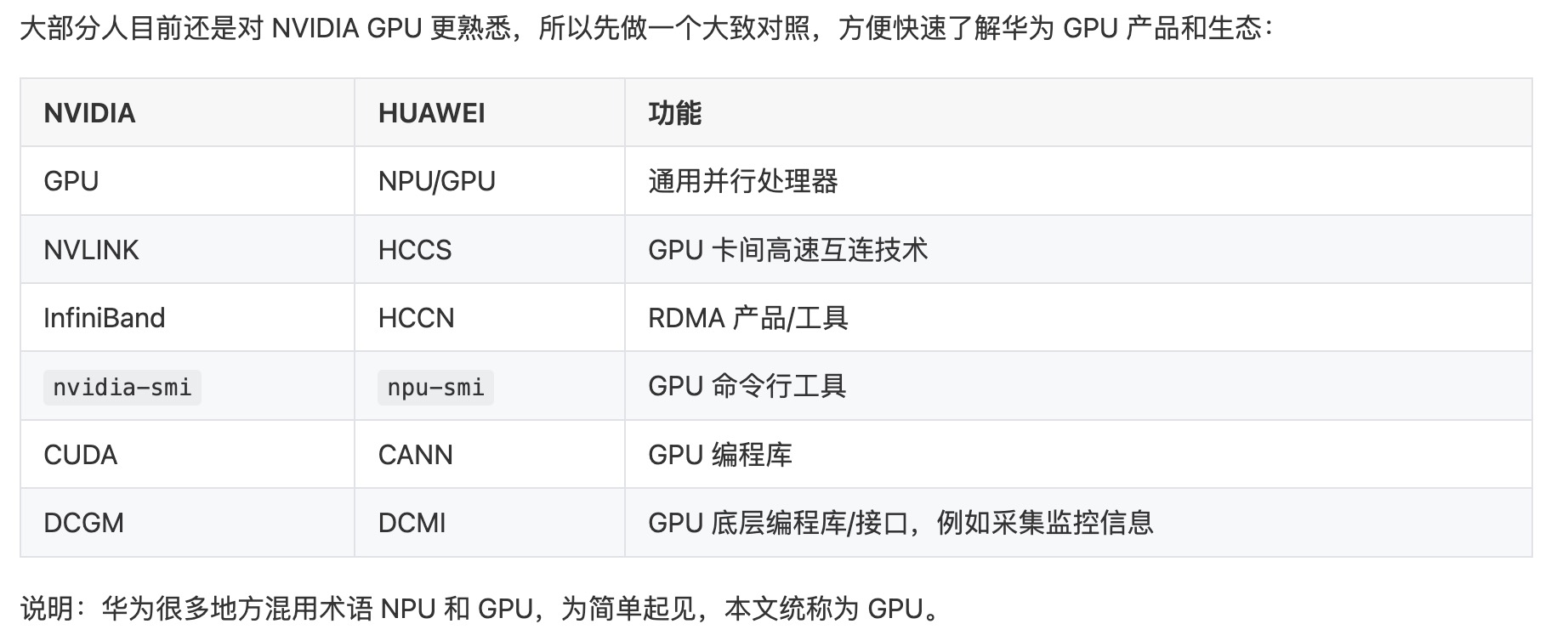
其他
- https://github.com/NVIDIA/k8s-device-plugin
- https://github.com/kubernetes/community/blob/master/contributors/design-proposals/resource-management/device-plugin.md
「如果这篇文章对你有用,请随意打赏」
如果这篇文章对你有用,请随意打赏
使用微信扫描二维码完成支付
